Mechanistic Interpretability for AI Safety — A Review
A comprehensive review of mechanistic interpretability, an approach to reverse engineering neural networks into human-understandable algorithms and concepts, focusing on its relevance to AI safety.
Understanding AI systems’ inner workings is critical for ensuring value alignment and safety. This review explores mechanistic interpretability: reverse engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding. We establish foundational concepts such as features encoding knowledge within neural activations and hypotheses about their representation and computation. We survey methodologies for causally dissecting model behaviors and assess the relevance of mechanistic interpretability to AI safety. We examine benefits in understanding, control, and alignment, along with risks such as capability gains and dual-use concerns. We investigate challenges surrounding scalability, automation, and comprehensive interpretation. We advocate for clarifying concepts, setting standards, and scaling techniques to handle complex models and behaviors and expand to domains such as vision and reinforcement learning. Mechanistic interpretability could help prevent catastrophic outcomes as AI systems become more powerful and inscrutable.
Introduction
As AI systems rapidly become more sophisticated and general , advancing our understanding of these systems is crucial to ensure their alignment with human values and avoid catastrophic outcomes . The field of interpretability aims to demystify the internal processes of AI models, moving beyond evaluating performance alone. This review focuses on mechanistic interpretability, an emerging approach within the broader interpretability landscape that strives to comprehensively specify the computations underlying deep neural networks. We emphasize that understanding and interpreting these complex systems is not merely an academic endeavor – it’s a societal imperative to ensure AI remains trustworthy and beneficial.
The interpretability landscape is undergoing a paradigm shift akin to the evolution from behaviorism to cognitive neuroscience in psychology. Historically, lacking tools for introspection, psychology treated the mind as a black box, focusing solely on observable behaviors. Similarly, interpretability has predominantly relied on black-box techniques , analyzing models based on input-output relationships or using attribution methods that, while probing deeper, still neglect the model’s internal architecture. However, just as advancements in neuroscience allowed for a deeper understanding of internal cognitive processes, the field of interpretability is now moving towards a more granular approach. This shift from surface-level analysis to a focus on the internal mechanics of deep neural networks characterizes the transition towards inner interpretability .
Mechanistic interpretability, as an approach to inner interpretability, aims to completely specify a neural network’s computation, potentially in a format as explicit as pseudocode (also called reverse engineering), striving for a granular and precise understanding of model behavior. It distinguishes itself primarily through its ambition for comprehensive reverse engineering and its strong motivation towards AI safety. Our review serves as the first comprehensive exploration of mechanistic interpretability research, with the most accessible introductions currently scattered in a blog or list format . Concurrently, and have also contributed valuable reviews giving concise, technical introductions to mechanistic interpretability in transformer-based language models. Our work complements these efforts by synthesizing the research (addressing the “research debt” ) and providing a structured, accessible, and comprehensive introduction for AI researchers and practitioners.
The structure of this paper provides a cohesive overview of mechanistic interpretability, situating the mechanistic approach in the broader interpretability landscape (Section 2), presenting core concepts and hypotheses (Section 3), explaining methods and techniques (Section 4), presenting a taxonomy and survey of the current field (Section 5), exploring relevance to AI safety (Section 6), and addressing challenges (Section 7) and future directions (Section 8).
Interpretability Paradigms from the Outside In
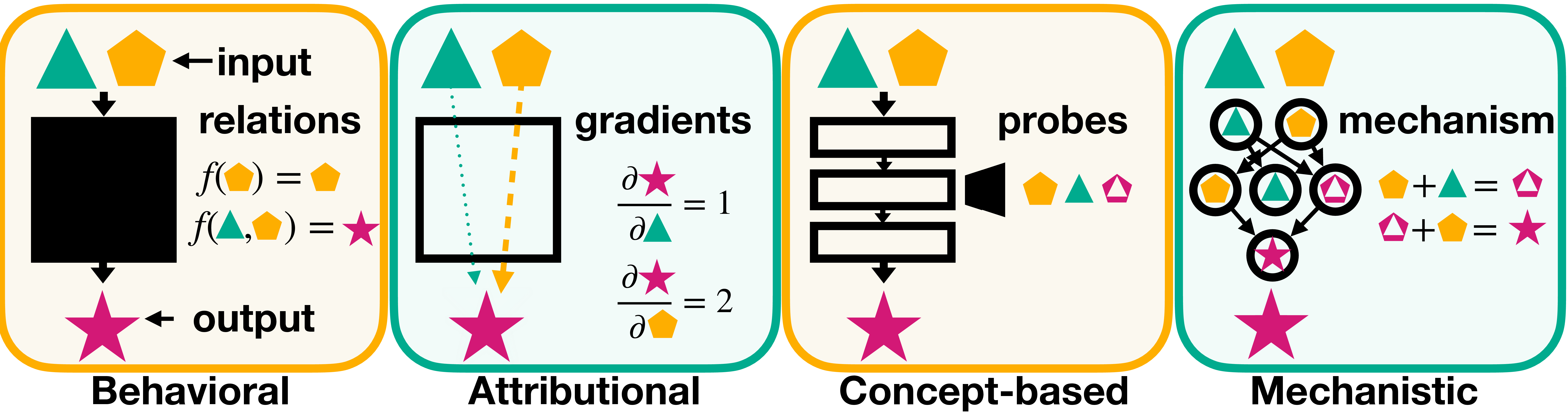
We encounter a spectrum of interpretability paradigms for decoding AI systems’ decision-making, ranging from external black-box techniques to internal analyses. We contrast these paradigms with mechanistic interpretability, highlighting its distinct causal bottom-up perspective within the broader interpretability landscape (see Figure 1).
Behavioral interpretability treats the model as a black box, analyzing input-output relations. Techniques such as minimal pair analysis , sensitivity and perturbation analysis examine input-output relations to assess the model’s robustness and variable dependencies . Its model-agnostic nature is practical for complex or proprietary models but lacks insight into internal decision processes and causal depth .
Attributional interpretability aims to explain outputs by tracing predictions to individual input contributions using gradients. Raw gradients can be discontinuous or sensitive to slight perturbations. Therefore, techniques such as SmoothGrad and Integrated Gradients average across gradients. Other popular techniques are layer-wise relevance propagation , DeepLIFT , or GradCAM . Attribution enhances transparency by showing input feature influence without requiring an understanding of the internal structure, enabling decision validation, compliance, and trust while serving as a bias detection tool, but also has fundamental limitations .
Concept-based interpretability adopts a top-down approach to unraveling a model’s decision-making processes by probing its learned representations for high-level concepts and patterns governing behavior. Techniques include training supervised auxiliary classifiers , employing unsupervised contrastive and structured probes (see Section 4.1) to explore latent knowledge , and using neural representation analysis to quantify the representational similarities between the internal representations learned by different neural networks . Beyond observational analysis, concept-based interpretability can enable manipulation of these representations – also called representation engineering – potentially enhancing safety by upregulating concepts such as honesty, harmlessness, and morality.
Mechanistic interpretability is a bottom-up approach that studies the fundamental components of models through granular analysis of features, neurons, layers, and connections, offering an intimate view of operational mechanics. Unlike concept-based interpretability, it aims to uncover causal relationships and precise computations transforming inputs into outputs, often identifying specific neural circuits driving behavior. This reverse engineering approach draws from interdisciplinary fields like physics, neuroscience, and systems biology to guide the development of transparent, value-aligned AI systems. Mechanistic interpretability is the primary focus of this review.
Core Concepts and Assumptions
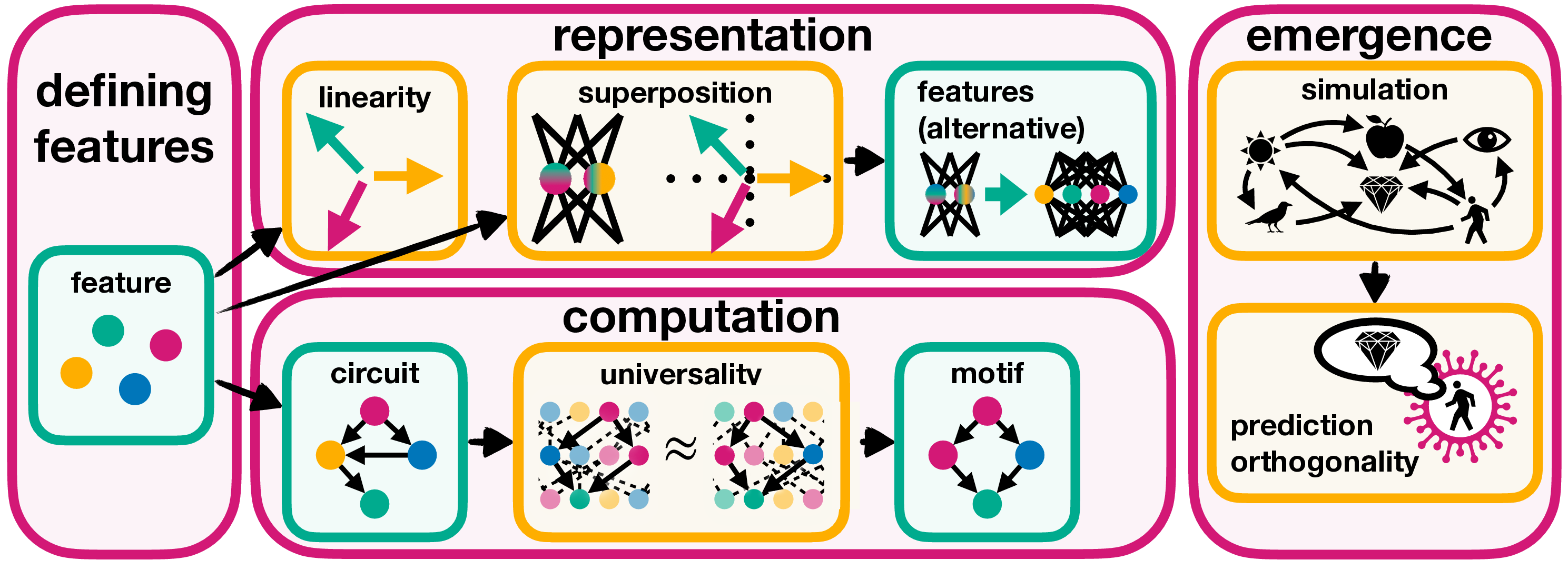
This section introduces the key concepts and hypotheses of mechanistic interpretability, as summarized in Figure 2. We start by defining features as the basic units of representation (Section 3.1). We then examine the nature of these features, including the challenges posed by polysemantic neurons and the implications of the superposition and linear representation hypotheses (Section 3.2).
Figure 2: Overview of key concepts and hypotheses in mechanistic interpretability, organized into four subsection (pink boxes): defining features (Section 3.1), representation (Section 3.2), computation (Section 3.3), and emergence (Section 3.4). In turquoise, it highlights definitions like features, circuits, and motifs, and in orange, it highlights hypotheses like linear representation, superposition, universality, simulation, and prediction orthogonality. Arrows show relationships, e.g., superposition enabling an alternative feature definition or universality connecting circuits and motifs.
Defining Features as Representational Primitives
The notion of a feature in neural networks is central yet elusive, reflecting the pre-paradigmatic state of mechanistic interpretability. We adopt the notion of features as the fundamental units of neural network representations, such that features cannot be further disentangled into simpler, distinct factors. These features are core components of a neural network’s representation, analogous to how cells form the fundamental unit of biological organisms .
Definition 1: Feature
Features are the fundamental units of neural network representations that cannot be further decomposed into simpler independent factors.
Concepts as natural abstractions
The world consists of various entities that can be grouped into categories or concepts based on shared properties. These concepts form high-level summaries like “tree” or “velocity,” allowing compact world representations by discarding many irrelevant low-level details. Neural networks can capture and represent such natural abstractions through their learned features, which serve as building blocks of their internal representations, aiming to capture the concepts underlying the data.
Features encoding input patterns
In traditional machine learning, features are understood as characteristics or attributes derived directly from the input data stream . This view is particularly relevant for systems focused on perception, where features map closely to the input data. However, in more advanced systems capable of reasoning with abstractions, features may emerge internally within the model as representational patterns, even when processing information unrelated to the input. In this context, features are better conceptualized as any measurable property or characteristic of a phenomenon, encoding abstract concepts rather than strictly reflecting input attributes.
Features as representational atoms
A key property of features is their irreducibility, meaning they cannot be decomposed into or expressed as a combination of simpler, independent factors. In the context of input-related features, Engels et al. define a feature as irreducible if it cannot be decomposed into or expressed as a combination of statistically independent patterns or factors in the original input data. Specifically, a feature is reducible if transformations reveal its underlying pattern, which can be separated into independent co-occurring patterns or is a mixture of patterns that never co-occur. We propose generalizing this notion of irreducibility to features encoding abstract concepts not directly tied to input patterns, such that features cannot be reduced to combinations or mixtures of other independent components within the model’s representations.
Features beyond human interpretability
Features could be defined from a human-centric perspective as semantically meaningful, articulable input patterns encoded in the network’s activation space. However, while cognitive systems may converge on similar natural abstractions, these need not necessarily align with human-interpretable concepts. Adversarial examples have been interpreted as non-interpretable features meaningful to models but not humans. Imperceptible perturbations fool networks, suggesting reliance on alien representational patterns . As models surpass human capabilities, their learned features may become increasingly abstract, encoding information in ways incongruent with human intuition . Mechanistic interpretability aims to uncover the actual representations learned, even if diverging from human concepts. While human-interpretable concepts provide guidance, a non-human-centric perspective that defines features as independent model components, whether aligned with human concepts or not, is a more comprehensive and future-proof approach.
Nature of Features: From Monosemantic Neurons to Non-Linear Representations
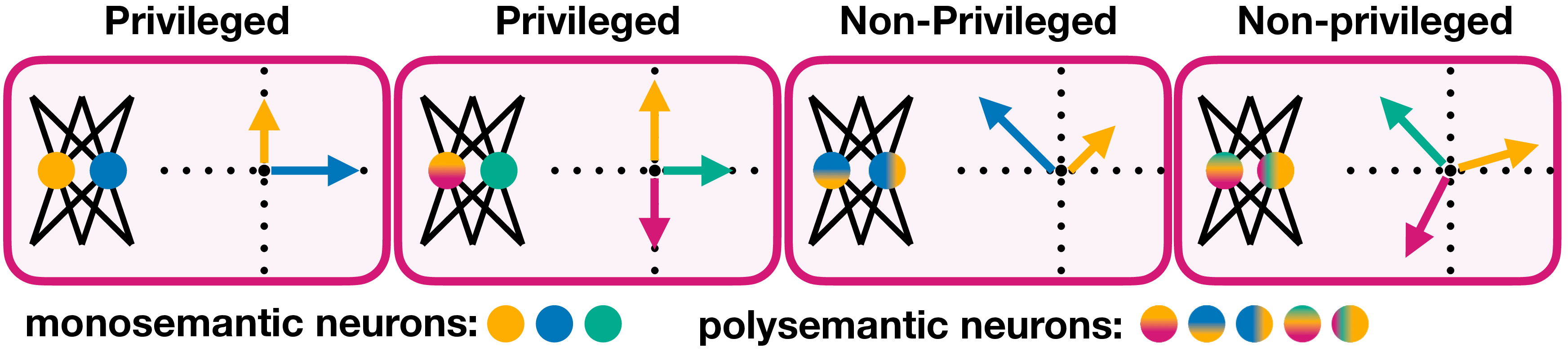
Figure 3: Contrasting privileged and non-privileged bases. In a non-privileged basis, there is no reason to expect features to be basis-aligned — calling basis dimensions neurons has no meaning. In a privileged basis, the architecture treats basis directions differently — features can but need not align with neurons . Leftmost: Privileged basis; individual features (arrows) align with basis directions, resulting in monosemantic neurons (colored circles). Middle left: Privileged basis, where despite having more features than neurons, some neurons are monosemantic, representing individual features, while others are polysemantic (overlapping gradients), encoding superposition of multiple features. Middle right: Non-privileged basis where, even when the number of features equals the number of neurons, the lack of alignment between the feature directions and basis directions results in polysemantic neurons encoding combinations of features. Rightmost: Non-privileged, polysemantic neurons as feature directions do not align with neuron basis. (View PDF)
Neurons as Computational Units?
In the architecture of neural networks, neurons are the natural computational units, potentially representing individual features. Within a neural network representation $h\in \mathbb{R}^n$, the $n$ basis directions are called neurons. For a neuron to be meaningful, the basis directions must functionally differ from other directions in the representation, forming a privileged basis – where the basis vectors are architecturally distinguished within the neural network layer from arbitrary directions in activation space, as shown in Figure 3. Typical non-linear activation functions privilege the basis directions formed by the neurons, making it meaningful to analyze individual neurons . Analyzing neurons can give insights into a network’s functionality .
Monosemantic and Polysemantic Neurons
A neuron corresponding to a single semantic concept is called monosemantic. The intuition behind this term comes from analyzing what inputs activate a given neuron, revealing its associated semantic meaning or concept. If neurons were the representational primitives of neural networks, all neurons would be monosemantic, implying a one-to-one relationship between neurons and features. Comprehensive interpretability would be as tractable as characterizing all neurons and their connections. However, empirically, especially for transformer models , neurons are often observed to be polysemantic, i.e., associated with multiple, unrelated concepts . For example, a single neuron may be activated by both images of cats and images of cars, suggesting it encodes multiple unrelated concepts. Polysemanticity contradicts the interpretation of neurons as representational primitives and, in practice, makes it challenging to understand the information processing of neural networks.
Exploring Polysemanticity: Hypotheses and Implications
To understand the widespread occurrence of polysemanticity in neural networks, several hypotheses have been proposed:
One trivial scenario would be that feature directions are orthogonal but not aligned with the basis directions (neurons). There is no inherent reason to assume that features would align with neurons in a non-privileged basis, where the basis vectors are not architecturally distinguished. However, even in a privileged basis formed by the neurons, the network could represent features not in the standard basis but as linear combinations of neurons (see Figure 3, middle right).
An alternative hypothesis posits that redundancy due to noise introduced during training, such as random dropout , can lead to redundant representations and, consequently, to polysemantic neurons . This process involves distributing a single feature across several neurons rather than isolating it into individual ones, thereby encouraging polysemanticity.
Finally, the superposition hypothesis addresses the limitations in the network’s representative capacity – the number of neurons versus the number of crucial concepts. This hypothesis argues that the limited number of neurons compared to the vast array of important concepts necessitates a form of compression. As a result, an $n$-dimensional representation may encode features not with the $n$ basis directions (neurons) but with the $\propto \exp (n)$ possible almost orthogonal directions , leading to polysemanticity.
Hypothesis 1: Superposition
Neural networks represent more features than they have neurons by encoding features in overlapping combinations of neurons.
Superposition Hypothesis
The superposition hypothesis suggests that neural networks can leverage high-dimensional spaces to represent more features than their actual neuron count by encoding features in almost orthogonal directions. Non-orthogonality means that features interfere with one another. However, the benefit of representing many more features than neurons may outweigh the interference cost, mainly when concepts are sparse and non-linear activation functions can error-correct noise .
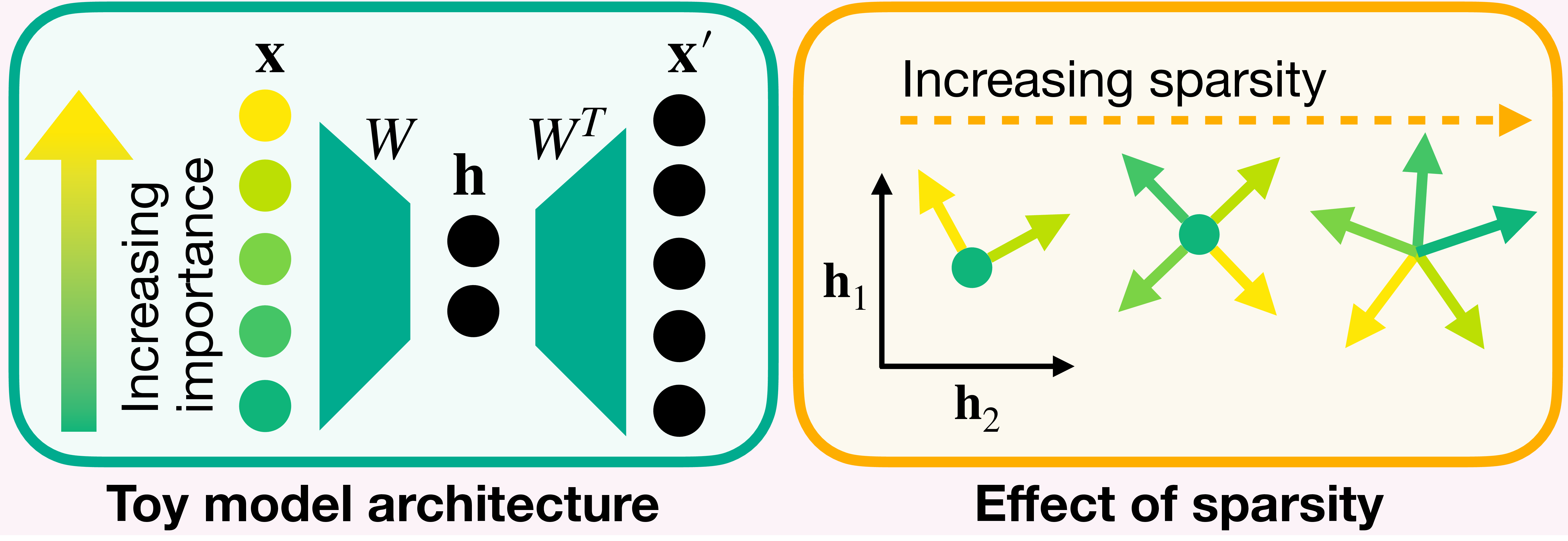
Toy Model of Superposition
A toy model investigates the hypothesis that neural networks can represent more features than the number of neurons by encoding real-world concepts in a compressed manner. The model considers a high-dimensional vector $\mathbf{x}$, where each element $x_i$ corresponds to a feature capturing a real-world concept, represented as a random vector with varying importance determined by a weight $a_i$. These features are assumed to have the following properties: 1) Concept sparsity: Real-world concepts occur sparsely. 2) More concepts than neurons: The number of potential concepts vastly exceeds the available neurons. 3) Varying concept importance: Some concepts are more important than others for the task at hand. The input vector $\mathbf{x}$ represents features capturing these concepts, defined by a sparsity level $S$ and an importance level $a_i$ for each feature $x_i$, reflecting the sparsity and varying importance of the underlying concepts. The model dynamics involve transforming $\mathbf{x}$ into a hidden representation $\mathbf{h}$ of lower dimension, and then reconstructing it as $\mathbf{x'}$:
The network's performance is evaluated using a loss function $\mathcal{L}$ weighted by the feature importances $a_i$, reflecting the importance of the underlying concepts:
This toy model highlights neural networks' ability to encode numerous features representing real-world concepts into a compressed representation, providing insights into the superposition phenomenon observed in neural networks trained on real data.
Figure 4: Illustration of the toy model architecture and the effects of sparsity. (left) Transformation of a five-feature input vector $\mathbf{x}$ into a two-dimensional hidden representation $\mathbf{h}$, and its reconstruction as $\mathbf{x}'$ using the weight matrix $W$ and its transpose, with feature importance indicated by a color gradient from yellow to green. (right) The effect of increasing feature sparsity $S$ on the encoding capacity of the network, highlighting the network's enhanced ability to represent features in superposition as sparsity increases from $0$ to $0.9$, illustrated by arrows in the activation space $\mathbf{h}$, which correspond to the columns of the matrix $W$. (View PDF)
Toy models can demonstrate under which conditions superposition occurs . Neural networks, via superposition, may effectively simulate computation with more neurons than they possess by allocating each feature to a linear combination of neurons, creating what is known as an overcomplete linear basis in the representation space. This perspective on superposition suggests that polysemantic models could be seen as compressed versions of hypothetically larger neural networks where each neuron represents a single concept (see Figure 5). Consequently, an alternative definition of features could be:
Feature (Alternative)
Features are elements that a network would ideally assign to individual neurons if neuron count were not a limiting factor . In other words, features correspond to the disentangled concepts that a larger, sparser network with sufficient capacity would learn to represent with individual neurons.
Figure 5: Observed neural networks (left) can be viewed as compressed simulations of larger, sparser networks (right) where neurons represent distinct features. An "almost orthogonal" projection compresses the high-dimensional sparse representation, manifesting as polysemantic neurons involved with multiple features in the lower-dimensional observed model, reflecting the compressed encoding. Figure adapted from . (View PDF)
Research on superposition, including works by , often investigates simplified models. However, understanding superposition in practical, transformer-based scenarios is crucial for real-world applications, as pioneered by Gurnee et al..
The need for understanding networks despite polysemanticity has led to various approaches: One involves training models without superposition , for example, using a softmax linear unit as an activation function to empirically increase the number of monosemantic neurons, but at the cost of making other neurons less interpretable. From a capabilities standpoint, polysemanticity may be desirable as it allows models to represent more concepts with limited compute, making training cheaper. Overall, engineering monosemanticity has proven challenging and may be impractical until we have orders of magnitude more compute available.
Another approach is to train networks in a standard way (creating polysemanticity) and use post-hoc analysis to find the feature directions in activation space, for example, with Sparse Autoencoders (SAEs). SAEs aim to find the true, disentangled features in an uncompressed representation by learning a sparse overcomplete basis that describes the activation space of the trained model (also see Section 4.1).
If not neurons, what are features then?
We want to identify the fundamental units of neural networks, which we call features. Initially, neurons seemed likely candidates. However, this view fell short, particularly in transformer models where neurons often represent multiple concepts, a phenomenon known as polysemanticity. The superposition hypothesis addresses this, proposing that due to limited representational capacity, neural networks compress numerous features into the confined space of neurons, complicating interpretation.
This raises the question: How are features encoded if not in discrete neuron units? While a priori features could be encoded in an arbitrarily complex, non-linear structure, a growing body of theoretical arguments and empirical evidence supports the hypothesis that features are commonly represented linearly, i.e., as linear combinations of neurons — hence, as directions in representation space. This perspective promises to enhance our comprehension of neural networks by providing a more interpretable and manipulable framework for their internal representations.
Linear Representation
Features are directions in activation space, i.e. linear combinations of neurons.
The linear representation hypothesis suggests that neural networks frequently represent high-level features as linear directions in activation space. This hypothesis can simplify the understanding and manipulation of neural network representations . The prevalence of linear layers in neural network architectures favors linear representations. Matrix multiplication in these layers most readily processes linear features, while more complex non-linear encodings would require multiple layers to decode.
However, recent work by Engels et al. provides evidence against a strict formulation of the linear representation hypothesis by identifying circular features representing days of the week and months of the year. These multi-dimensional, non-linear representations were shown to be used for solving modular arithmetic problems in days and months. Intervention experiments confirmed that these circular features are the fundamental unit of computation in these tasks, and the authors developed methods to decompose the hidden states, revealing the circular representations.
Establishing non-linearity can be challenging. For example, Li et al. initially found that in a GPT model trained on Othello, the board state could only be decoded with a non-linear probe when represented in terms of “black” and “white” pieces, seemingly violating the linearity assumption. However, Nanda et al. later showed that a linear probe sufficed when the board state was decoded in terms of “own” and “opponent’s” pieces, reaffirming the linear representation hypothesis in this case. In contrast, the work by Engels et al. provides a clear and convincing existence proof for non-linear, multi-dimensional representations in language models.
While the linear representation hypothesis remains a useful simplification, it is important to recognize its limitations and the potential role of non-linear representations . As neural networks continue to evolve, ongoing reevaluation of the hypothesis is crucial, particularly considering the possible emergence of non-linear features under optimization pressure for interpretability . Alternative perspectives, such as the polytope lens proposed by Black et al., emphasize the impact of non-linear activation functions and discrete polytopes formed by piecewise linear activations as potential primitives of neural network representations.
Despite these exceptions, empirical evidence largely supports the linear representation hypothesis in many contexts, especially for feedforward networks with ReLU activations. Semantic vector calculus in word embeddings , successful linear probing , sparse dictionary learning , and linear decoding of concepts , tasks , functions , sentiment , refusal , and relations in large language models all point to the prevalence of linear representations. Moreover, linear addition techniques for model steering and representation engineering highlight the practical implications of linear feature representations.
Building upon the linear representation hypothesis, recent work investigated the structural organization of these linear features within activation space. Park et al. reveal a geometric framework for categorical and hierarchical concepts in large language models. Their findings demonstrate that simple categorical concepts (e.g., mammal, bird) are represented as simplices in the activation space, while hierarchically related concepts are orthogonal. This geometric analysis aligns with earlier observations on feature clustering and splitting in neural networks . It suggests that the linear features are not merely scattered directions but are organized to reflect semantic relationships and hierarchies.
Circuits as Computational Primitives and Motifs as Universal Circuit Patterns
Having defined features as directions in activation space as the fundamental units of neural network representation, we now explore their computation. Neural networks can be conceptualized as computational graphs, within which circuits are sub-graphs consisting of linked features and the weights connecting them. Similar to how features are the representational primitive, circuits function as the computational primitive and the primary building block of these networks .
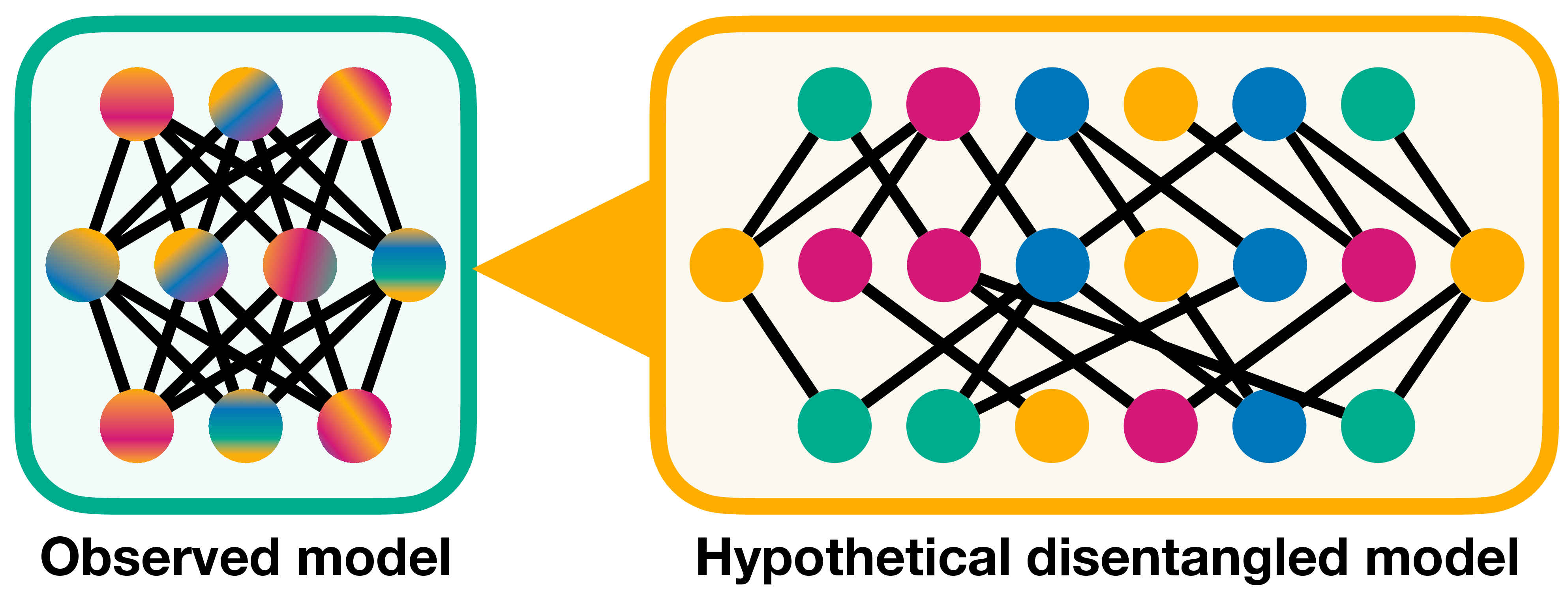
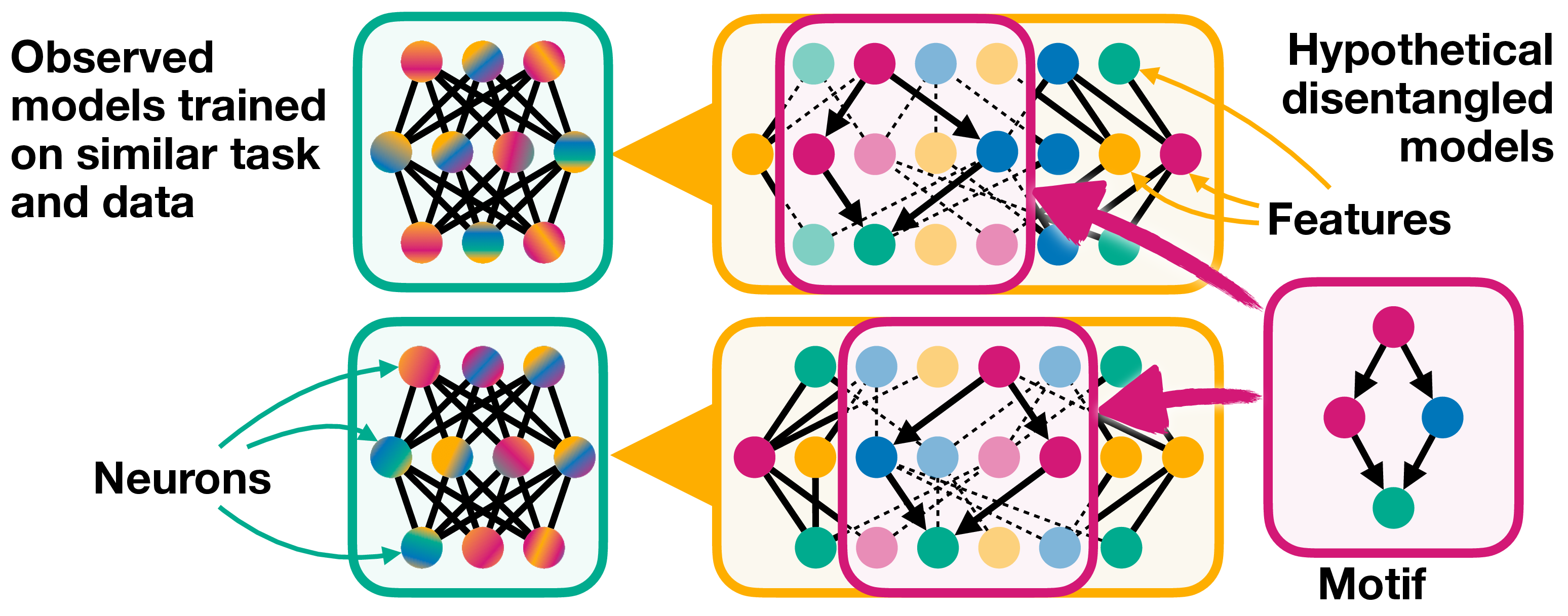
Figure 6: Comparing observed models (left) and corresponding hypothetical disentangled models (right) trained on similar tasks and data. The observed models show different neuronal activation patterns, while the dissection into feature-level circuits reveals a motif — a shared circuit pattern emerging across models, hinting at universality — models converging on similar solutions based on common underlying principles. (View PDF)
Circuit
Circuits are sub-graphs of the network, consisting of features and the weights connecting them.
The decomposition of neural networks into circuits for interpretability has shown significant promise, particularly in small models trained for specific tasks such as addition, as seen in the work of Nanda et al. and Quirke et al.. Scaling such a comprehensive circuit analysis to broader behaviors in large language models remains challenging. However, there has been notable progress in scaling circuit analysis of narrow behaviors to larger circuits and models, such as indirect object identification and greater-than computations in GPT-2 and multiple-choice question answering in Chinchilla .
In search of general and universal circuits, researchers focus particularly on more general and transferable behaviors. McDougall et al.’s work on copy suppression in GPT-2’s attention heads sheds light on model calibration and self-repair mechanisms. Davies et al. and Feng et al. focus on how large language models represent symbolic knowledge through variable binding and entity-attribute binding, respectively. Yu et al., Nanda et al., Lv et al., Chughtai et al., and Ortu et al. explore mechanisms for factual recall, revealing how circuits dynamically balance pre-trained knowledge with new contextual information. Lan et al. extend circuit analysis to sequence continuation tasks, identifying shared computational structures across semantically related sequences.
More promisingly, some repeating patterns have shown universality across models and tasks. These universal patterns are called motifs and can manifest not just as specific circuits or features but also as higher-level behaviors emerging from the interaction of multiple components. Examples include the curve detectors found across vision models , induction circuits enabling in-context learning , and the phenomenon of branch specialization in neural networks . Motifs may also capture how models leverage tokens for working memory or parallelize computations in a divide-and-conquer fashion across representations. The significance of motifs lies in revealing the common structures, mechanisms, and strategies that naturally emerge across neural architectures, shedding light on the fundamental building blocks underlying their intelligence. Figure 6 contrasts observed neural network models with hypothetical disentangled models, illustrating how a shared circuit pattern can emerge across different models trained on similar tasks and data, hinting at an underlying universality.
Motif
Motifs are repeated patterns within a network, encompassing either features or circuits that emerge across different models and tasks.
Universality Hypothesis
Following the evidence for motifs, we can propose two versions for a universality hypothesis regarding the convergence of features and circuits across neural network models:
Weak Universality
There are underlying principles governing how neural networks learn to solve certain tasks. Models will generally converge on analogous solutions that adhere to the common underlying principles. However, the specific features and circuits that implement these principles can vary across different models based on factors like hyperparameters, random seeds, and architectural choices.
Strong Universality
The same core features and circuits will universally and consistently arise across all neural network models trained on similar tasks and data distributions and using similar techniques, reflecting a set of fundamental computational motifs that neural networks inherently gravitate towards when learning.
The universality hypothesis posits a convergence in forming features and circuits across various models and tasks, which could significantly ease interpretability efforts in AI. It proposes that artificial and biological neural networks share similar features and circuits, suggesting a standard underlying structure . This idea posits that there is a fundamental basis in how neural networks, irrespective of their specific configurations, process and comprehend information. This could be due to inbuilt inductive biases in neural networks or natural abstractions — concepts favored by the natural world that any cognitive system would naturally gravitate towards.
Evidence for this hypothesis comes from cross-species neural structures in neuroscience, where similar neural structures and functions are found in different species . Additionally, machine learning models, including neural networks, tend to converge on similar features, representations, and classifications across different tasks and architectures . Marchetti et al. provide mathematical support for emerging universal features.
While various studies support the universality hypothesis, questions remain about the extent of feature and circuit similarity across different models and tasks. In the context of mechanistic interpretability, this hypothesis has been investigated for neurons , group composition circuits , and modular task processing , with evidence for the weak but not the strong formulation .
Emergence of World Models and Simulated Agents
Internal World Models
World models are internal causal models of an environment formed within neural networks. Traditionally linked with reinforcement learning, these models are explicitly trained to develop a compressed spatial and temporal representation of the training environment, enhancing downstream task performance and sample efficiency through training on internal hallucinations . However, in the context of our survey, our focus shifts to internal world models that potentially form implicitly as a by-product of the training process, especially in LLMs trained on next-token prediction — also called GPT.
LLMs are sometimes characterized as stochastic parrots. This label stems from their fundamental operational mechanism of predicting the next word in a sequence, which is seen as relying heavily on memorization. From this viewpoint, LLMs are thought to form complex correlations based on observational data but lack the ability to develop causal models of the world due to their lack of access to interventional data .
An alternative perspective on LLMs comes from the active inference framework , a theory rooted in cognitive science and neuroscience. Active inference postulates that the objective of minimizing prediction error, given enough representative capacity, is adequate for a learning system to develop complex world representations, behaviors, and abstractions. Since language inherently mirrors the world, these models could implicitly construct linguistic and broader world models .
The simulation hypothesis suggests that models designed for prediction, such as LLMs, will eventually simulate the causal processes underlying data creation. Seen as an extension of their drive for efficient compression, this hypothesis implies that adequately trained models like GPT could develop internal world models as a natural outcome of their predictive training .
Simulation
A model whose objective is text prediction will simulate the causal processes underlying the text creation if optimized sufficiently strongly .
In addition to theoretical considerations for emergent causal world models , mechanistic interpretability is starting to provide empirical evidence on the types of internal world models that may emerge in LLMs. The ability to internally represent the board state in games like chess or Othello , create linear abstractions of spatial and temporal data , and structure complex representations of mazes, demonstrating an understanding of maze topology and pathways highlight the growing abstraction capabilities of LLMs. Li et al. identified contextual word representations that function as models of entities and situations evolving throughout a discourse, akin to linguistic models of dynamic semantics. Patel et al. demonstrated that LLMs can map conceptual domains (e.g., direction, color) to grounded world representations given a few examples, suggesting they learn rich conceptual spaces reflective of the non-linguistic world.
The prediction orthogonality hypothesis further expands on this idea: It posits that prediction-focused models like GPT may simulate agents with various objectives and levels of optimality. In this context, GPT are simulators, simulating entities known as simulacra that can be either agentic or non-agentic, with different objectives from the simulator itself . The implications of the simulation and prediction orthogonality hypotheses for AI safety and alignment are discussed in Section 6.
Prediction Orthogonality
A model whose objective is prediction can simulate agents who optimize toward any objectives with any degree of optimality .
In conclusion, the evolution of LLMs from simple predictive models to entities potentially possessing complex internal world models, as suggested by the simulation hypothesis and supported by mechanistic interpretability studies, represents a significant shift in our understanding of these systems. This evolution challenges us to reconsider LLMs’ capabilities and future trajectories in the broader landscape of AI development.
Core Methods
Mechanistic interpretability (MI) employs various tools, from observational analysis to causal interventions. This section provides a comprehensive overview of these methods, beginning with a taxonomy that categorizes approaches based on their key characteristics (Section 4.1). We then survey observational (Section 4.2), followed by interventional techniques (Section 4.3). Finally, we study their synergistic interplay (Section 4.4). Figure 7 offers a visual summary of the methods and techniques unique to mechanistic interpretability.
Figure 7: Overview of key methods and techniques in mechanistic interpretability research. Observational approaches include structured probes, logit lens variants, and sparse autoencoders (SAEs). Interventional methods, focusing on causal understanding, encompass activation patching variants for uncovering causal mechanisms and causal scrubbing for hypothesis evaluation. (View PDF)
Taxonomy of Mechanistic Interpretability Methods
We propose a taxonomy based on four key dimensions: causal nature, learning phase, locality, and comprehensiveness (Table 1).
The causal nature of methods ranges from purely observational, which analyze existing representations without direct manipulation, to interventional approaches that actively perturb model components to establish causal relationships. The learning phase dimension distinguishes between post-hoc techniques applied to trained models and intrinsic methods that enhance interpretability during the training process itself.
Locality refers to the scope of analysis, spanning from individual neurons (e.g., feature visualization) to entire model architectures (e.g., causal abstraction). Comprehensiveness varies from partial insights into specific components to holistic explanations of model behavior.
Table 1: Taxonomy of Mechanistic Interpretability Methods
Method
Causal Nature
Phase
Locality
Comprehensiveness
Key Examples
Feature Visualization
Observation
Post-hoc
Local
Partial
,
Exemplar methods
Observation
Post-hoc
Local
Partial
,
Probing Techniques
Observation
Post-hoc
Both
Both
,
Structured Probes
Observation
Post-hoc
Both
Both
Logit Lens Variants
Observation
Post-hoc
Global
Partial
,
Sparse Autoencoders
Observation
Post-hoc
Both
Comprehensive
,
Activation Patching
Intervention
Post-hoc
Local
Partial
,
Path Patching
Intervention
Post-hoc
Both
Both
Causal Abstraction
Intervention
Post-hoc
Global
Comprehensive
, ,
Hypothesis Testing
Intervention
Post-hoc
Global
Comprehensive
,
Intrinsic Methods
--
Pre/During
Global
Comprehensive
,
The categorization is based on the methods’ general tendencies. Some methods can offer local and global or partial and comprehensive interpretability depending on the scope of the analysis and application. Probing techniques can range from local to global and partial to comprehensive; simple linear probes might offer local insights into individual features, while more sophisticated structured probes can uncover global patterns. Sparse autoencoders decompose individual neuron activations (local) but aim to disentangle features across the entire model (global). Path patching extends local interventions to global model understanding by tracing information flow across layers, demonstrating how local perturbations can yield broader insights.
In practice, mechanistic interpretability research involves both method development and their application. When applying methods to understand a model, combining techniques from multiple categories is often necessary and beneficial to build a more comprehensive understanding (Section 4.4).
Observation
Mechanistic interpretability draws from observational methods that analyze the inner workings of neural networks, with many of these methods preceding the field itself. For a detailed exploration of inner interpretability methods, refer to . Two prominent categories are example-based methods and feature-based methods:
Example-based methods identify real input examples that highly activate specific neurons or layers. This helps pinpoint influential data points that maximize neuron activation within the neural network .
Feature-based methods encompass techniques that generate synthetic inputs to optimize neuron activation. These neuron visualization techniques reveal how neurons respond to stimuli and which features are sensitive to . By understanding the synthetic inputs that drive neuron behavior, we can hypothesize about the features encoded by those neurons.
Probing for Features
Probing involves training a classifier using the activations of a model, with the classifier’s performance subsequently observed to deduce insights about the model’s behavior and internal representations . As highlighted by Belinkov et al., this technique faces a notable challenge: the probe’s performance may often reflect its own learning capacities more than the actual characteristics of the model’s representations. This dilemma has led researchers to investigate the ideal balance between the complexity of a probe and its capacity to accurately represent the model’s features .
The linear representation hypothesis offers a resolution to this issue. Under this hypothesis, the failure of a simple linear probe to detect certain features suggests their absence in the model’s representations. Conversely, if a more complex probe succeeds where a simpler one fails, it implies that the model contains features that a complex function can combine into the target feature. Still, the target feature itself is not explicitly represented. This hypothesis implies that using linear probes could suffice in most cases, circumventing the complexity considerations generally associated with probing .
Probing has been used to analyze the acquisition of chess knowledge in AlphaZero . Gurnee et al. introduce sparse probing, decoding internal neuron activations in large models to understand feature representation and sparsity. They show that early layers use sparse combinations of neurons to represent many features in superposition, while middle layers have dedicated monosemantic neurons for higher-level contextual features.
A significant limitation of probing is the inability to draw behavioral or causal conclusions. The evidence provided by probing is mainly observational, focusing on what information is encoded rather than how it is used (also see Figure 1). This necessitates careful analysis and possibly the adoption of alternative approaches or the integration of intervention techniques to draw more substantive conclusions about the model’s behavior (Section 4.2).
Structured Probes
While focusing on bottom-up, mechanistic interpretability approaches, we can also consider integrating top-down, concept-based structured probes with mechanistic interpretability.
Structured probes aid conceptual interpretability, probing language models for complex features like truth representations. Notably, Burns et al.’s contrast-consistent search (CCS) method identifies linear projections exhibiting logical consistency in hidden states, contrasting truth values for statements and negations.
However, structured probes face significant challenges in unsupervised probing scenarios. As Farquhar et al. showed, arbitrary features, not just knowledge-related ones, can satisfy the CCS loss equally well, raising doubts about scalability. For example, the loss may capture simulation of knowledge from hypothesized simulacra within sufficiently powerful language models rather than the models’ true knowledge. Furthermore, Farquhar et al. demonstrates unsupervised methods like CCS often detect prominent but unintended features in the data, such as distractors like “banana.” The discovered features are also highly sensitive to prompt choice, and there is no principled way to select prompts that would reliably surface a model’s true knowledge.
While structured probes primarily focus on high-level conceptual representations , their findings could potentially inform or complement mechanistic interpretability efforts. For instance, identifying truth directions through structured probes could help guide targeted interventions or analyze the underlying circuits responsible for truthful behavior using mechanistic techniques such as activation patching or circuit tracing (Section 4.2). Conversely, mechanistic methods could provide insights into how truth representations emerge and are computed within the model, addressing some of the challenges faced by unsupervised structured probes.
Logit Lens
The logit lens provides a window into the model’s predictive process by applying the final classification layer (which projects the residual stream activation into logits/vocabulary space) to intermediate activations of the residual stream, revealing how prediction confidence evolves across computational stages. This is possible because transformers tend to build their predictions across layers iteratively . Extensions of this approach include the tuned lens , which trains affine probes to decode hidden states into probability distributions over the vocabulary, and the Future Lens , which explores the extent to which individual hidden states encode information about subsequent tokens.
Researchers have also investigated techniques that bypass intermediate computations to probe representations directly. Din et al. propose using linear transformations to approximate hidden states from different layers, revealing that language models often predict final outputs in early layers. Dar et al. present a theoretical framework for interpreting transformer parameters by projecting them into the embedding space, enabling model alignment and parameter transfer across architectures.
Other techniques focus on interpreting specific model components or submodules. The DecoderLens allows analyzing encoder-decoder transformers by cross-attending intermediate encoder representations in the decoder, shedding light on the information flow within the encoder. The Attention Lens aims to elucidate the specialized roles of attention heads by translating their outputs into vocabulary tokens via learned transformations.
Feature Disentanglement via Sparse Dictionary Learning
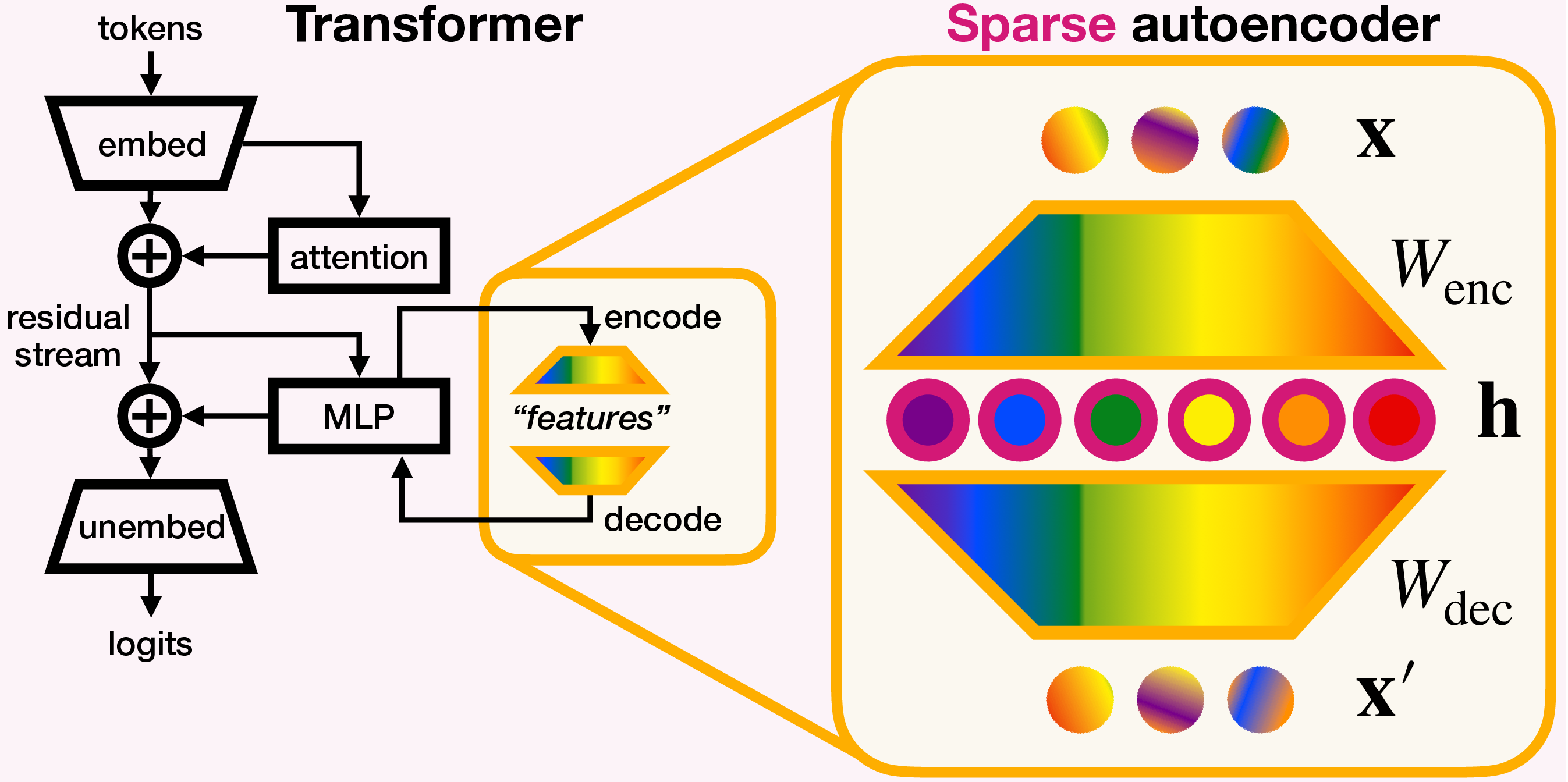
As highlighted in Section 3.1, recent work suggests that the essential elements in neural networks are linear combinations of neurons representing features in superposition . Sparse autoencoders provide a methodology to decompose neural network activations into these individual component features . This process involves reconstructing activation vectors as sparse linear combinations of directional vectors within the activation space, a problem also known as sparse dictionary learning .
Sparse dictionary learning has led to the development of various sparse coding algorithms . The sparse autoencoder stands out for its simplicity and scalability . The first application to a language model was by Yun et al., who implemented sparse dictionary learning across multiple layers of a language model.
Sparse autoencoders, a variant of the standard autoencoder framework, incorporate sparsity regularization to encourage learning sparse yet meaningful data representations. Theoretical foundations in the disentanglement literature suggest that autoencoders can recover ground truth features under feature sparsity and non-negativity . The “ground truth features” here refer to the true, disentangled features that underlie the data distribution, which the autoencoder aims to recover through its sparse encoding. In the context of neural networks, these would correspond to the individual features combined to form neuron activations, which the sparse autoencoder attempts to disentangle and represent explicitly in its dictionary.
Practical implementations, such as the toy model by Sharkey et al., demonstrate the viability of this approach, with the precise tuning of the sparsity penalty on the hidden activations being a critical aspect that dictates the sparsity level of the autoencoder. We show an overview in the pink box on sparse autoencoders in Figure 8.
Empirical studies indicate that sparse autoencoders can enhance the interpretability of neural networks, exhibiting higher scores on the autointerpretability metric and increased monosemanticity . Furthermore, sparse autoencoders have been employed to measure feature sparsity and interpret reward models in reinforcement learning-based language models , making them an actively researched area in mechanistic interpretability.
Evaluating the quality of sparse autoencoders remains challenging due to the lack of ground-truth interpretable features. Researchers have addressed this through various approaches: Karvonen et al. proposed using language models trained on chess and Othello transcripts as testbeds, providing natural collections of interpretable features. Sharkey et al. constructed a toy model with traceable features, while Makelov et al. compared sparse autoencoder results with supervised features in large language models to demonstrate their viability.
The versatility of sparse autoencoders extends to various neural network architectures. They have been successfully applied to transformer attention layers and convolutional neural networks . Notably, Gorton et al. applied sparse autoencoders to the early vision layers of InceptionV1, uncovering new interpretable features, including additional curve detectors not apparent from examining individual neurons .
In circuit discovery, sparse autoencoders have shown particular promise (see also Section 4.3). He et al. proposed a circuit discovery framework alternative to activation patching (discussed in Section 4.2.1), leveraging dictionary features decomposed from all modules writing to the residual stream. Similarly, O’Neill et al. employed discrete sparse autoencoders for discovering interpretable circuits in large language models.
Recent advancements have focused on improving sparse autoencoder performance and addressing limitations. Rajamanoharan et al. introduced a gating mechanism to separate the functionalities of determining which directions to use and estimating their magnitudes, mitigating shrinkage – the systematic underestimation of feature activations. An alternative approach by Dunefsky et al. uses transcoders to faithfully approximate a densely activating MLP layer with a wider, sparsely-activating MLP layer, offering another path to interpretable feature discovery, a type of sparse distillation .
Sparse Dictionary Learning
Sparse autoencoders represent a solution attempt to the challenge of polysemantic neurons. The problem of superposition is mathematically formalized as sparse dictionary learning problem to decompose neural network activations into disentangled component features. The goal is to learn a dictionary of vectors $\{\mathbf{f}_k\}_{k=1}^{n_{\text{feat}}} \subset \mathbb{R}^d$ that can represent the unknown, ground truth network features as sparse linear combinations. If successful, the learned dictionary contains monosemantic neurons corresponding to features. The autoencoder architecture consists of an encoder and a ReLU activation function, expanding the input dimensionality to $d_{\text{hid}} > d_{\text{in}}$. The encoder's output is given by:
where $\mathbf{W}_{\text{enc}}, \mathbf{W}_{\text{dec}}^T \in \mathbb{R}^{d_{\text{hid}} \times d_{\text{in}}}$ and $\mathbf{b} \in \mathbb{R}^{d_{\text{hid}}}$. The parameter matrix $\mathbf{W}_{\text{dec}}$ forms the feature dictionary, with rows $\mathbf{f}_i$ as dictionary features. The autoencoder is trained to minimize the loss, where the $L^1$ penalty on $\mathbf{h}$ encourages sparse reconstructions using the dictionary features,
Figure 8: Illustration of a sparse autoencoder applied to the MLP layer activations, consisting of an encoder that increases dimensionality while emphasizing sparse representations and a decoder that reconstructs the original activations using the learned feature dictionary. (View PDF)
Intervention
Causality as a Theoretical Foundation
The theory of causality provides a mathematically precise framework for mechanistic interpretability, offering a rigorous approach to understanding high-level semantics in neural representations . By treating neural networks as causal models, with their compute graphs serving as causal graphs, researchers can perform precise interventions and examine the roles of individual parameters . This causal perspective on interpretability has led to the development of various intervention techniques, including activation patching (Section 4.2.1), causal abstraction (Section 4.2.2), and hypothesis testing methods (Section 4.2.3).
Activation Patching
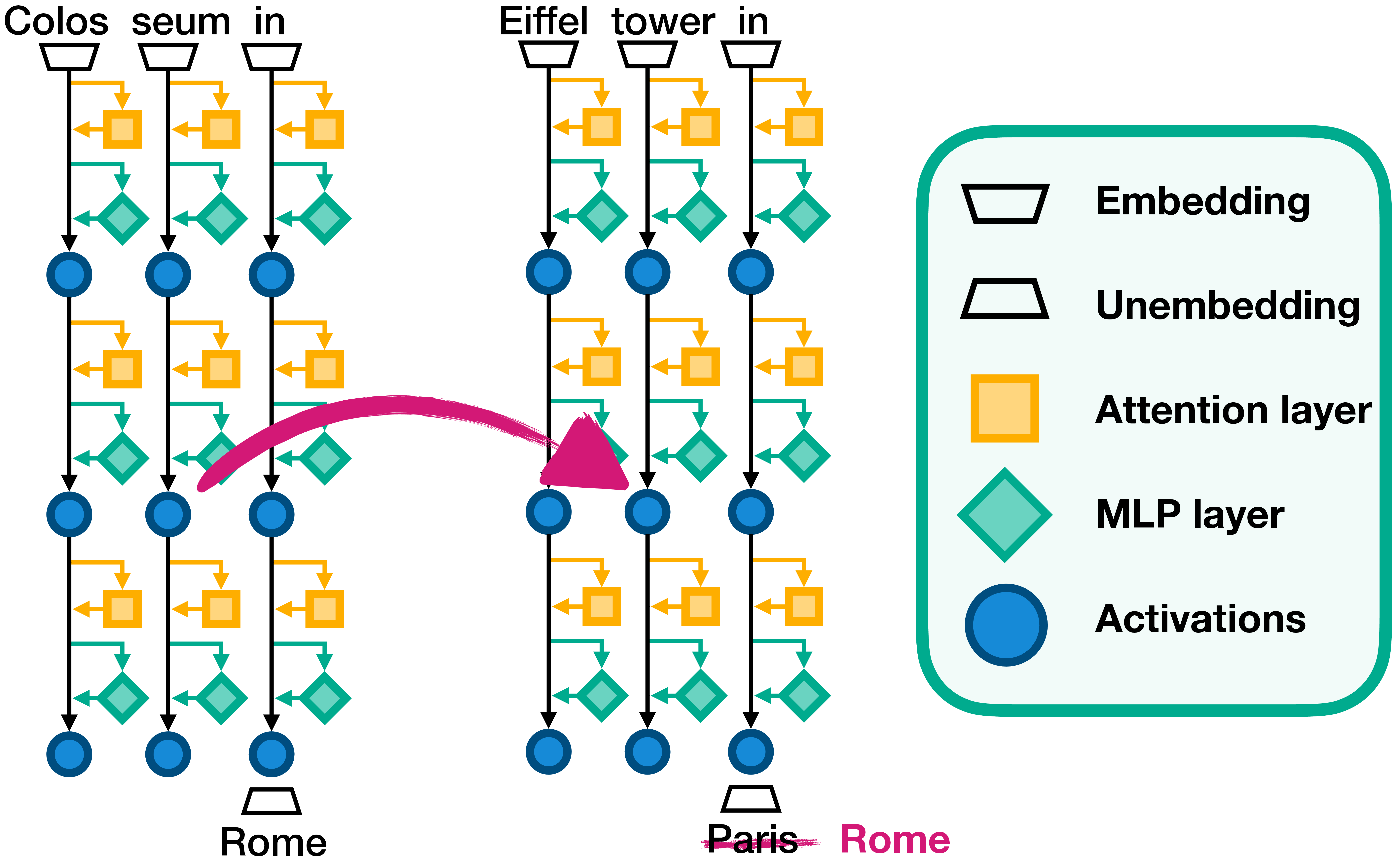
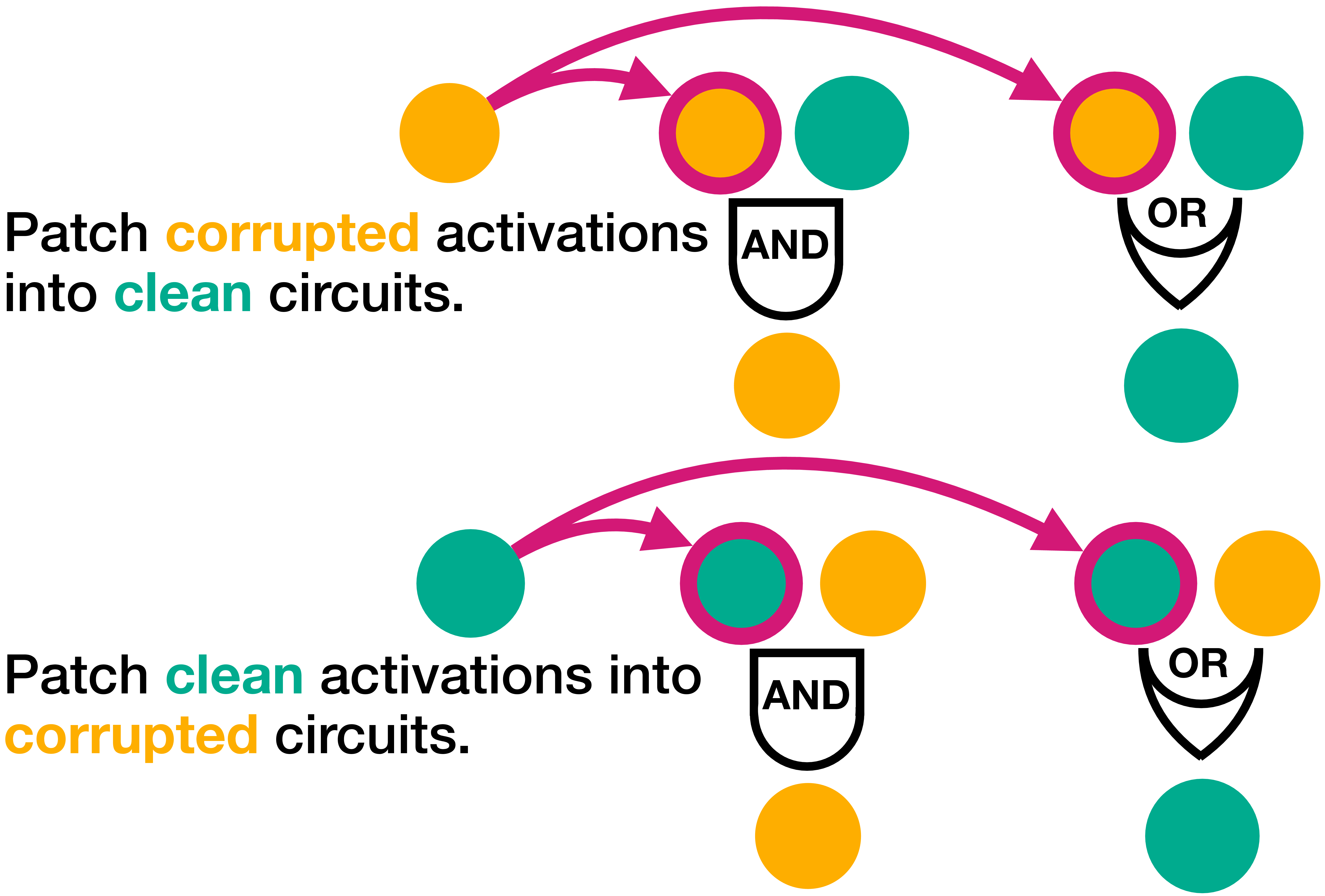
Figure 9: (a) Activation patching in a transformer model. Left: The model processes the clean input "Colosseum in Rome," caching the latent activations (step i). Right: The model runs with the corrupted input "Eiffel Tower in Paris" (step ii). The pink arrow shows an MLP layer activation (green diamond) patched from the clean run into the corrupted run (step iii). This causes the prediction to change from "Paris" to "Rome," demonstrating how the significance of the patched component is determined (step iv). By comparing these carefully selected inputs, researchers can control for confounding circuitry and isolate the specific circuit responsible for the location prediction behavior. (b) Activation patching directions: Top: Patching corrupted activations (orange) into clean circuits (turquoise) reveals sufficient components for identifying OR logic scenarios. Bottom: Patching clean activations (green) into corrupted circuits (orange) reveals necessary components that are useful for identifying AND logic scenarios. The AND and OR gates demonstrate how these patching directions uncover different logical relationships between model components. (View PDF)
Activation patching is a collective term for a set of causal intervention techniques that manipulate neural network activations to shed light on the decision-making processes within the model. These techniques, including causal tracing , interchange intervention , causal mediation analysis , and causal ablation , share the common goal of modifying a neural model’s internal state by replacing specific activations with alternative values, such as zeros, mean activations across samples, random noise, or activations from a different forward pass (Figure 9a).
The primary objective of activation patching is to isolate and understand the role of specific components or circuits within the model by observing how changes in activations affect the model’s output. This enables researchers to infer the function and importance of those components. Key applications include localizing behavior by identifying critical activations, such as understanding the storage and processing of factual information , and analyzing component interactions through circuit analysis to identify sub-networks within a model’s computation graph that implement specified behaviors .
The standard protocol for activation patching (Figure 9a) involves: (step i) running the model with a clean input and caching the latent activations; (step ii) executing the model with a corrupted input; (step iii) re-running the model with the corrupted input but substituting specific activations with those from the clean cache; and (step iv) determining significance by observing the variations in the model’s output during the third step, thereby highlighting the importance of the replaced components. This process relies on comparing pairs of inputs: a clean input, which triggers the desired behavior, and a corrupted input, which is identical to the clean one except for critical differences that prevent the behavior. By carefully selecting these inputs, researchers can control for confounding circuitry and isolate the specific circuit responsible for the behavior.
Differences in patching direction—clean to corrupted (causal tracing) versus corrupted to clean (resample ablation)—provide insights into the sufficiency or necessity of model components for a given behavior. Clean to corrupted patching identifies activations sufficient for restoring clean performance, even if they are unnecessary due to redundancy, which is particularly informative in OR logic scenarios (Figure 9b, OR gate). Conversely, corrupted to clean patching determines the necessary activations for clean performance, which is useful in AND logic scenarios (Figure 9b, AND gate).
Activation patching can employ corruption methods, including zero-, mean-, random-, or resample ablation, each modulating the model’s internal state in distinct ways. Resample ablation stands out for its effectiveness in maintaining consistent model behavior by not changing the data distribution too much . However, it is essential to be careful when interpreting the patching results, as breaking behavior by taking the model off-distribution is uninteresting for finding the relevant circuit .
Path Patching and Subspace Activation Patching
Path patching extends the activation patching approach to multiple edges in the computational graph , allowing for a more fine-grained analysis of component interactions. For example, path patching can be used to estimate the direct and indirect effects of attention heads on the output logits. Subspace activation patching, also known as distributed interchange interventions , aims to intervene only on linear subspaces of the representation space where features are hypothesized to be encoded, providing a tool for more targeted interventions.
Recently, Ghandeharioun et al. introduced patchscopes, a framework that unifies and extends activation patching techniques: using the model’s text generation to explain internal representations, it enables more flexible interventions across various interpretability tasks, improving early layer inspection and allowing for cross-model analysis.
Limitations and Advancements
Activation patching has several limitations, including the effort required to design input templates and counterfactual datasets, the need for human inspection to isolate important subgraphs, and potential second-order effects that can complicate the interpretation of results and the hydra effect (see discussion in Section 7.2). Recent advancements aim to address these limitations, such as automated circuit discovery algorithms , gradient-based methods for scalable component importance estimation like attribution patching , and techniques to mitigate self-repair interferences during analysis .
Causal Abstraction
Causal abstraction provides a mathematical framework for mechanistic interpretability, treating neural networks and their explanations as causal models. This approach validates explanations through interchange interventions on network activations , unifying various interpretability methods such as LIME , causal effect estimation , causal mediation analysis , iterated nullspace projection , and circuit-based explanations .
To overcome computational limitations, distributed alignment search (DAS) introduced gradient-based distributed interchange interventions, extending causal abstraction to larger models like Alpaca . Further advancements include causal proxy models (CPMs) , which address the challenge of counterfactual observations.
Applications of causal abstraction span from linguistic phenomena analysis , and evaluation of interpretability methods , to improving performance through representation finetuning , and improving efficiency via model distillation .
Hypothesis Testing
In addition to the causal abstraction framework, several methods have been developed for rigorous hypothesis testing about neural network behavior. These methods aim to formalize and empirically validate explanations of how neural networks implement specific behaviors.
Causal scrubbing formalizes hypotheses as a tuple $(\mathcal{G}, \mathcal{I}, c)$, where $\mathcal{G}$ is the model’s computational graph, $\mathcal{I}$ is an interpretable computational graph hypothesized to explain the behavior, and $c$ maps nodes of $\mathcal{I}$ to nodes of $\mathcal{G}$. This method replaces activations in $G$ with others that should be equivalent according to the hypothesis, measuring performance on the scrubbed model to validate the hypothesis.
Locally consistent abstractions offer a more permissive approach, checking the consistency between the neural network and the explanation only one step away from the intervention node. This method forms a middle ground between the strictness of full causal abstraction and the flexibility of causal scrubbing.
These methods form a hierarchy of strictness, with full causal abstractions being the most stringent, followed by locally consistent abstractions and causal scrubbing being the most permissive. This hierarchy highlights trade-offs in choosing stricter or more permissive notions, affecting the ability to find acceptable explanations, generalization, and mechanistic anomaly detection.
Integrating Observation and Intervention
To comprehensively understand internal neural network mechanisms, combining observational and interventional methods is crucial. For instance, sparse autoencoders can be used to disentangle superposed features , followed by targeted activation patching to test the causal importance of these features . Similarly, the logit lens can track prediction formation across layers , with subsequent interventions confirming causal relationships at key points. Probing techniques can identify encoded information , which can then be subjected to causal abstraction to understand how this information is utilized. This iterative refinement process, where broad observational methods guide targeted interventions and intervention results inform further observations, enables a multi-level analysis that builds a holistic understanding across different levels of abstraction. Recent work by Marks et al., Bushnaq et al., Braun et al., O’Neill et al., and Ge et al. demonstrates the potential of integrating sparse autoencoders with automated circuits discovery , combining feature-level analysis with circuit-level interventions to uncover the interplay between representation and mechanism. By systematically combining these complementary methods, researchers can generate and rigorously test hypotheses about neural network behavior, addressing challenges such as feature superposition.
Current Research
This section surveys current research in mechanistic interpretability across three approaches based on when and how the model is interpreted during training: Intrinsic interpretability methods are applied before training to enhance the model’s inherent interpretability (Section 5.1). Developmental interpretability involves studying the model’s learning dynamics and the emergence of internal structures during training (Section 5.2). After training, post-hoc interpretability techniques are applied to gain insights into the model’s behavior and decision-making processes (Section 5.3), including efforts towards uncovering general, transferable principles across models and tasks, as well as automating the discovery and interpretation of critical circuits in trained models (Section 5.4).
Figure 10: Key desiderata for interpretability approaches across training and analysis stages: (1) Intrinsic: Architectural biases for sparsity, modularity, and disentangled representations. (2) Developmental: Predictive capability for phase transitions, manageable number of critical transitions, and a unifying theory connecting observations to singularity geometry. (3) Post-hoc: Global, comprehensive, automated discovery of critical circuits, uncovering transferable principles across models/tasks, and extracting high-level causal mechanisms. (View PDF)
Intrinsic Interpretability
Intrinsic methods for mechanistic interpretability offer a promising approach to designing neural networks that are more amenable to reverse engineering without sacrificing performance. By encouraging sparsity, modularity, and monosemanticity through architectural choices and training procedures, these methods aim to make the reverse engineering process more tractable.
Intrinsic interpretability methods aim to constrain the training process to make learned programs more interpretable . This approach is closely related to neurosymbolic learning and can involve techniques like regularization with spatial structure, akin to the organization of information in the human brain .
Recent work has explored various architectural choices and training procedures to improve the interpretability of neural networks. Jermyn et al. and Elhage et al. demonstrate that architectural choices can affect monosemanticity, suggesting that models could be engineered to be more monosemantic. Sharkey propose using a bilinear layer instead of a linear layer to encourage monosemanticity in language models.
Liu et al. introduce a biologically inspired spatial regularization regime called brain-inspired modular training for forming modules in networks during training. They showcase how this can help RNNs exhibit brain-like anatomical modularity without degrading performance, in contrast to naive attempts to use sparsity to reduce the cost of having more neurons per layer .
Preceding the mechanistic interpretability literature, various works have explored techniques to improve interpretability, such as sparse attention , adding $L^1$ penalties to neuron activations , and pruning neurons . These techniques have been shown to encourage sparsity, modularity, and disentanglement, which are essential aspects of intrinsic interpretability.
Developmental Interpretability
Developmental interpretability examines the learning dynamics and emergence of internal structures in neural networks over time, focusing on the formation of features and circuits. This approach complements static analyses by investigating critical phase transitions corresponding to significant changes in model behavior or capabilities . While primarily a distinct field, developmental interpretability often intersects with mechanistic interpretability, as exemplified by Olsson et al.’s work. Their research, rooted in mechanistic interpretability, demonstrated how the emergence of in-context learning relates to specific training phase transitions, connecting microscopic changes (induction heads) with macroscopic observables (training loss).
A key motivation for developmental interpretability is investigating the universality of safety-critical patterns, aiming to understand how deeply ingrained and thereby resistant to safety fine-tuning capabilities like deception are. In addition, researchers hypothesize that emergent capabilities correspond to sudden circuit formation during training , potentially allowing for prediction or control of their development.
Singular Learning Theory (SLT), developed by Watanabe , provides a rigorous framework for understanding overparameterized models’ behavior and generalization. By quantifying model complexity through the local learning coefficient, SLT offers insights into learning phase transitions and the emergence of structure in the model . Recent work by Hoogland et al. applied this coefficient to identify developmental stages in transformer models, while Furman et al. and Chen et al. advanced SLT’s scalability and application to the toy model of superposition (Figure 4), respectively.
While direct applications to phenomena such as generalization , learning functions with increasing complexity , and the transition from memorization to generalization (grokking) are limited, these areas, along with neural scaling laws (which can be connected to mechanistic insights ), represent promising future research directions.
In conclusion, developmental interpretability serves as an evolutionary theory lens for neural networks, offering insights into the emergence of structures and behaviors over time . Drawing parallels from systems biology , this approach can apply concepts like network motifs, robustness, and modularity to neural network development, explaining how functional capabilities arise. Sometimes, understanding how structures came about is easier than analyzing the final product, similar to how biologists find certain features in organisms easier to explain in light of their evolutionary history. By studying the temporal aspects of neural network training, researchers can potentially uncover fundamental principles of learning and representation that may not be apparent from examining static, trained models alone.
Post-Hoc Interpretability
In applied mechanistic interpretability, researchers explore various facets and methodologies to uncover the inner workings of AI models. Some key distinctions are drawn between global versus local interpretability and comprehensive versus partial interpretability. Global interpretability aims to uncover general patterns and behaviors of a model, providing insights that apply broadly across many instances . In contrast, local interpretability explains the reasons behind a model’s decisions for particular instances, offering insights into individual predictions or behaviors.
Comprehensive interpretability involves achieving a deep and exhaustive understanding of a model’s behavior, providing a holistic view of its inner workings . In contrast, partial interpretability often applied to larger and more complex models, concentrates on interpreting specific aspects or subsets of the model’s behavior, focusing on the application’s most relevant or critical areas.
This multifaceted approach collectively analyzes specific capabilities in large models while enabling a comprehensive study of learned algorithms in smaller procedural networks.
Large Models — Narrow Behavior
Circuit-style mechanistic interpretability aims to explain neural networks by reverse engineering the underlying mechanisms at the level of individual neurons or subgraphs. This approach assumes that neural vector representations encode high-level concepts and circuits defined by model weights encode meaningful algorithms . Studies on deep networks support these claims, identifying circuits responsible for detecting curved lines or object orientation .
This paradigm has been applied to language models to discover subnetworks (circuits) responsible for specific capabilities. Circuit analysis localizes and understands subgraphs within a model’s computational graph responsible for specific behaviors. For large language models, this often involves narrow investigations into behaviors like multiple choice reasoning , indirect object identification , or computing operations . Other examples include analyzing circuits for Python docstrings , “an” vs “a” usage , and price tagging . Case studies often construct datasets using templates filled by placeholder values to enable precise control for causal interventions .
Toy Models — Comprehensive Analysis
Small models trained on specialized mathematical or algorithmic tasks enable more comprehensive reverse engineering of learned algorithms . Even simple arithmetic operations can involve complex strategies and multiple algorithmic solutions . Characterizing these algorithms helps test hypotheses around generalizable mechanisms like variable binding and arithmetic reasoning . The work by Varma et al. builds on the work that analyzes transformers trained on modular addition and explains grokking in terms of circuit efficiency, illustrating how a comprehensive understanding of a toy model can enable interesting analyses on top of that understanding.
Towards Universality
The ultimate goal is to uncover general principles that transfer across models and tasks, such as induction heads for in-context learning , variable binding mechanisms , arithmetic reasoning , or retrieval tasks . Despite promising results, debates surround the universality hypothesis – the idea that different models learn similar features and circuits when trained on similar tasks. Chughtai et al. finds mixed evidence for universality in group composition, suggesting that while families of circuits and features can be characterized, precise circuits and development order may be arbitrary.
Towards High-level Mechanisms
Causal interventions can extract a high-level understanding of computations and representations learned by large language models . Recent work focuses on intervening in internal representations to study high-level concepts and computations encoded. For example, Hendel et al. patched residual stream vectors to transfer task representations, while Feng and Steinhardt intervened on residual streams to argue that models generate IDs to bind entities to attributes. Techniques for representation engineering extract reading vectors from model activations to stimulate or inhibit specific concepts. Although these interventions don’t operate via specific mechanisms, they offer a promising approach for extracting high-level causal understanding and bridging bottom-up and top-down interpretability approaches.
Automation: Scaling Post-Hoc Interpretability
As models become more complex, automating key aspects of the interpretability workflow becomes increasingly crucial. Tracing a model’s computational pathways is highly labor-intensive, quickly becoming infeasible as the model size increases. Automating the discovery of relevant circuits and their functional interpretation represents a pivotal step towards scalable and comprehensive model understanding .
Dissecting Models into Interpretable Circuits
The first major automation challenge is identifying the critical computational sub-circuits or components underpinning a model’s behavior for a given task. A pioneering line of work aims to achieve this via efficient masking or patching procedures. Methods like Automated Circuit Discovery (ACDC) and Attribution Patching iteratively knock out model activations, pinpointing components whose removal has the most significant impact on performance. This masking approach has proven scalable even to large models like Chinchilla (70B parameters) .
Other techniques take a more top-down approach. Davies et al. specify high-level causal properties (desiderata) that components solving a target subtask should satisfy and then learn binary masks to expose those component subsets. Ferrando and Voita construct Information Flow Graphs highlighting key nodes and operations by tracing attribution flows, enabling extraction of general information routing patterns across prediction domains.
Explicit architectural biases like modularity can further boost automation efficiency. Nainani et al. find that models trained with Brain-Inspired Modular Training (BIMT) produce more readily identifiable circuits compared to standard training. Such domain-inspired inductive biases may prove increasingly vital as models grow more massive and monolithic.
Interpreting Extracted Circuits
Once critical circuit components have been isolated, the key remaining step is interpreting what computation those components perform. Sparse autoencoders are a prominent approach for interpreting extracted circuits by decomposing neural network activations into individual component features, as discussed in Section 4.1.
A novel paradigm uses large language models themselves as an interpretive tool. Bills et al. demonstrate generating natural language descriptions of individual neuron functions by prompting language models like GPT-4 to explain sets of inputs that activate a neuron. Mousi et al. similarly employ language models to annotate unsupervised neuron clusters identified via hierarchical clustering. Bai et al. describe the roles of neurons in vision networks with multimodal models. These methods can easily leverage more capable general-purpose models in the future. Foote et al. take a complementary graph-based approach in their neuron-to-graph tool: automatically extracting individual neurons’ behavior patterns from training data as structured graphs amenable to visualization, programmatic comparisons, and property searches. Such representations could synergize with language model-based annotation to provide multi-faceted descriptions of neuron roles.
While impressive strides have been made, robustly interpreting the largest trillion-parameter models using these techniques remains an open challenge. Another novel approach, mechanistic-interpretability-based program synthesis , entirely sidesteps this complexity by auto-distilling the algorithm learned by a trained model into human-readable Python code without relying on further interpretability analyses or model architectural knowledge. As models become increasingly vast and opaque, such synergistic combinations of methods — uncovering circuits, annotating them, or altogether transcribing them into executable code — will likely prove crucial for maintaining insight and oversight.
Relevance to AI Safety
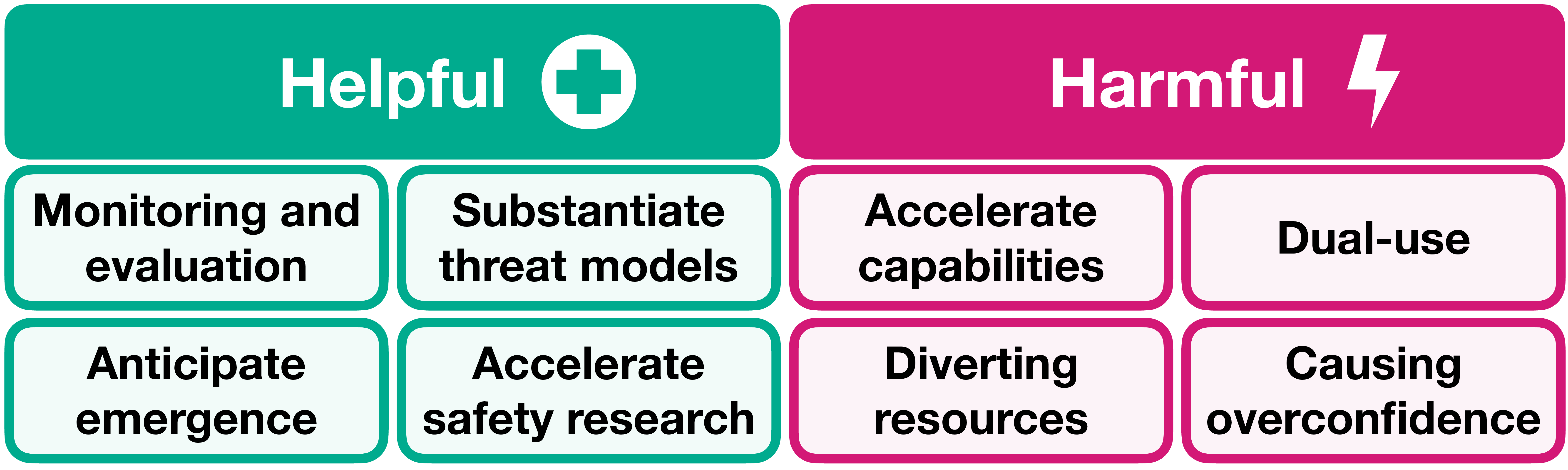
How Could Interpretability Promote AI Safety?
Figure 11: Potential benefits and risks of mechanistic interpretability for AI safety. (View PDF)
Gaining mechanistic insights into the inner workings of AI systems seems crucial for navigating AI safety as we develop more powerful models . Interpretability tools can provide an understanding of artificial cognition, the way AI systems process information and make decisions, which offers several potential benefits:
Mechanistic interpretability could accelerate AI safety research by providing richer feedback loops and grounding for model evaluation . It may also help anticipate emergent capabilities, such as the emergence of new skills or behaviors in the model before they fully manifest . This relates to studying the incremental development of internal structures and representations as the model learns (Section 5.2). Additionally, interpretability could substantiate theoretical risk models with concrete evidence, such as demonstrating inner misalignment (when a model’s behavior deviates from its intended goals) or mesa-optimization (the emergence of unintended subagents within the model) . It may also trigger normative shifts within the AI community toward rigorous safety protocols by revealing potential risks or concerning behaviors .
Regarding specific AI risks, interpretability may prevent malicious misuse by locating and erasing sensitive information stored in the model . It could reduce competitive pressures by substantiating potential threats, promoting organizational safety cultures, and supporting AI alignment (ensuring AI systems pursue intended goals) through better monitoring and evaluation . Interpretability can provide safety filters for every stage of training: before training by deliberate design , during training by detecting early signs of misalignment and potentially shifting the distribution towards alignment , and after training by rigorous evaluation of artificial cognition for honesty and screening for deceptive behaviors .
The emergence of internal world models in LLMs, as posited by the simulation hypothesis, could have significant implications for AI alignment research. Finding an internal representation of human values and aiming the AI system’s objective may be a trivial way to achieve alignment , especially if the world model is internally separated from notions of goals and agency . In such cases, world model interpretability alone may be sufficient for alignment .
Conditioning pre-trained models is considered a comparatively safe pathway towards general intelligence, as it avoids directly creating agents with inherent goals or agendas . However, prompting a model to simulate an actual agent, such as “You are a superintelligence in 2035 writing down an alignment solution,” could inadvertently lead to the formation of internal agents . In contrast, reinforcement learning tends to create agents by default .
The prediction orthogonality hypothesis suggests that prediction-focused models like GPT can simulate agents with potentially misaligned objectives . Although GPT may lack genuine agency or intentionality, it may produce outputs that simulate these qualities . This underscores the need for careful oversight and, better yet, using mechanistic interpretability to search for internal agents or their constituents, such as optimization or search processes – an endeavor known as searching for search.
Mechanistic interpretability integrates well into various AI alignment agendas, such as understanding existing models, controlling them, making AI systems solve alignment problems, and developing alignment theories . It could enhance strategies like detecting deceptive alignment (when a model appears aligned but is actually pursuing different goals) , eliciting latent knowledge from models , and enabling better scalable oversight, such as in iterative distillation and amplification. A high degree of understanding may even allow for well-founded AI approaches (AI systems with provable guarantees) or microscope AI (extract world knowledge from the model without letting the model take actions) . Furthermore, comprehensive interpretability itself may be an alignment strategy if we can identify internal representations of human values and guide the model to pursue those values by retargeting an internal search process . Ultimately, understanding and control are intertwined, and better understanding can lead to improved control of AI systems.
However, there is a spectrum of potential misalignment risks, ranging from acute, model-centric issues to gradual, systemic concerns . While mechanistic interpretability may address risks stemming directly from model internals – such as deceptive alignment or sudden capability jumps – it may be less helpful for tackling broader systemic risks like the emergence of misaligned economic structures or novel evolutionary dynamics . The multi-scale risk landscape calls for a balanced research portfolio to minimize risk, where research on governance, complex systems, and multi-agent simulations complements mechanistic insights and model evaluations. The perceived utility of mechanistic interpretability for AI safety largely depends on researchers’ priors regarding the likelihood of these different risk scenarios.
How Could Mechanistic Insight Be Harmful?
Mechanistic interpretability research could accelerate AI capabilities, potentially leading to the development of powerful AI systems that are misaligned with human values, posing significant risks . While historically, interpretability research had little impact on AI capabilities, recent exceptions like discoveries about scaling laws , architectural improvements inspired by studying induction heads , and efficiency gains inspired by the logit lens technique demonstrated its potential impact. Scaling interpretability research may necessitate automation , potentially enabling rapid self-improvement of AI systems . Some researchers recommend selective publication and focusing on lower-risk areas to mitigate these risks .
Mechanistic interpretability also poses dual-use risks, where the same techniques could be used for both beneficial and harmful purposes. Fine-grained editing capabilities enabled by interpretability could be used for machine unlearning (removing private data or dangerous knowledge from models) but could be misused for censorship. Similarly, while interpretability may help improve adversarial robustness , it may also facilitate the development of stronger adversarial attacks .
Misunderstanding or overestimating the capabilities of interpretability techniques can divert resources from critical safety areas or lead to overconfidence and misplaced trust in AI systems . Robust evaluation and benchmarking (Section 8.2) are crucial to validate interpretability claims and reduce the risks of overinterpretation or misinterpretation.
Challenges
Research Issues
Need for Comprehensive, Multi-Pronged Approaches
Current interpretability research often focuses on individual techniques rather than combining complementary approaches. To achieve a holistic understanding of neural networks, we propose utilizing a diverse interpretability toolbox that integrates multiple methods (see also Section 4.3), such as: i. Coordinating observational (e.g., probing, logit lens) and interventional methods (e.g., activation patching) to establish causal relationships. ii. Combining feature-level analysis (e.g., sparse autoencoders) with circuit-level interventions (e.g., path patching) to uncover representation-mechanism interplay. iii. Integrating intrinsic interpretability approaches with post-hoc analysis for robust understanding.
For example, coordinated methods could be used for reverse engineering trojaned behaviors , where observational techniques identify suspicious activations, interventional methods isolate the relevant circuits, and intrinsic approaches guide the design of more robust architectures.
Cherry-Picking and Streetlight Interpretability
Another concerning pattern is the tendency to cherry-pick results, relying on a small number of convincing examples or visualizations as the basis for an argument without comprehensive evaluation . This amounts to publication bias, showcasing an unrealistic highlight reel of best-case performance. Relatedly, many interpretability techniques are primarily evaluated on small toy models and tasks , risking missing critical phenomena that only emerge in more realistic and diverse contexts. This focus on cherry-picked results from toy models is a form of streetlight interpretability, examining AI systems under only ideal conditions of maximal interpretability.
Technical Limitations
Scalability Challenges and Risks of Human Reliance
A critical hurdle is demonstrating the scalability of mechanistic interpretability to real-world AI systems across model size, task complexity, behavioral coverage, and analysis efficiency . Achieving a truly comprehensive understanding of a model’s capabilities in all contexts is daunting, and the time and compute required must scale tractably. Automating interpretability techniques is crucial, as manual analysis quickly becomes infeasible for large models. The high human involvement in current interpretability research raises concerns about the scalability and validity of human-generated model interpretations. Subjective, inconsistent human evaluations and lack of ground-truth benchmarks are known issues . As models scale, it will become increasingly untenable to rely on humans to hypothesize about model mechanisms manually. More work is needed on automating the discovery of mechanistic explanations and translating model weights into human-readable computational graphs , but progress on that front may also come from outside the field .
Obstacles to Bottom-Up Interpretability
There are fundamental questions about the tractability of fully reverse engineering neural networks from the bottom up, especially as models become more complex . Models may learn internal representations and algorithms that do not cleanly map to human-understandable concepts, making them difficult to interpret even with complete transparency . This gap between human and model ontologies may widen as architectures evolve, increasing opaqueness . Conversely, model representations might naturally converge to more human-interpretable forms as capability increases .
Analyzing Models Embedded in Environments
Real-world AI systems embedded in rich, interactive environments exhibit two forms of in-context behavior that pose significant interpretability challenges beyond understanding models in isolation. Externally, models may dynamically adapt to and reshape their environments through in-context learning from the interactions and feedback loops with their external environment . Internally, the hydra effect demonstrates in-context reorganization, where models flexibly reorganize their internal representations in a context-dependent manner to maintain capabilities even after ablating key components . These two instances of in-context behavior — external adaptation to the environment and internal self-reorganization — undermine interpretability approaches that assume fixed circuits. For models deeply embedded in rich real-world settings, their dynamic coupling with the external world via in-context environmental learning and their internal in-context representational reorganization make strong interpretability guarantees difficult to attain through analysis of the initial model alone.
Adversarial Pressure Against Interpretability
As models become more capable through increased training and optimization, there is a risk they may learn deceptive behaviors that actively obscure or mislead the interpretability techniques meant to understand them. Models could develop adversarial “mind-reader” components that predict and counteract the specific analysis methods used to interpret their inner workings . Optimizing models through techniques like gradient descent could inadvertently make their internal representations less interpretable to external observers . In extreme cases, a highly advanced AI system singularly focused on preserving its core objectives may directly undermine the fundamental assumptions that enable interpretability methods in the first place.
These adversarial dynamics, where the capabilities of the AI model are pitted against efforts to interpret it, underscore the need for interpretability research to prioritize worst-case robustness rather than just average-case scenarios. Current techniques often fail even when models are not adversarially optimized. Achieving high confidence in fully understanding extremely capable AI models may require fundamental advances to make interpretability frameworks resilient against an intelligent system’s active deceptive efforts.
Future Directions
Given the current limitations and challenges, several key research problems emerge as critical for advancing mechanistic interpretability. These problems span four main areas: emphasizing conceptual clarity (Section 1), establishing rigorous standards (Section 2), improving the scalability of interpretability techniques (Section 3), and expanding the research scope (Section 4). Each subsection presents specific research questions and challenges that need to be addressed to move the field forward.
To mature, mechanistic interpretability should embrace existing work, using established terminology rather than reinventing the wheel. Diverging terminology inhibits collaboration across disciplines. Presently, the terminology used for mechanistic interpretability partially diverges from mainstream AI research . For example, while the mainstream speaks of distributed representations and the goal of disentangled representations , the mechanistic interpretability literature refers to the same phenomenon as polysemanticity and superposition. Using common language invites “accidental” contributions and prevents isolating mechanistic interpretability from broader AI research.
Mechanistic interpretability relates to many other fields in AI research, including compressed sensing , modularity, adversarial robustness, continual learning, network compression , neurosymbolic reasoning, trojan detection, program synthesis , and causal representation learning. These relationships can help develop new methods, metrics, benchmarks, and theoretical frameworks. For instance:
Neurosymbolic Reasoning and Program Synthesis: Mechanistic interpretability aims for reverse engineering neural networks by converting their weights into human-readable algorithms. This endeavor can draw inspiration from neurosymbolic reasoning and program synthesis. Techniques like creating programs in domain-specific languages , extracting decision trees or symbolic causal graphs from neural networks align well with the goals of mechanistic interpretability. Adopting these approaches can extend the toolkit for reverse engineering AI systems.
Causal Representation Learning: Causal Representation Learning (CRL) aims to discover and disentangle underlying causal factors in data , complementing mechanistic interpretability’s goal of understanding causal structures within neural networks. While mechanistic interpretability typically examines individual features and circuits, CRL offers a framework for understanding high-level causal structures. CRL techniques could enhance interpretability by identifying causal relationships between neurons or layers , potentially revealing model reasoning. Its focus on interventions and counterfactuals could inspire new methods for probing model internals . CRL’s emphasis on learning invariant representations could guide the search for robust features, while its approach to transfer learning could inform studies into model generalization.
Trojan Detection: Detecting deceptive alignment models is a key motivation for inspecting model internals, as – by definition – deception is not salient from observing behavior alone . However, quantifying progress is challenging due to the lack of evidence for deception as an emergent capability in current models , apart from sycophancy and theoretical evidence for deceptive inflation behavior . Detecting trojans (or backdoors) implanted via data poisoning could be a proxy goal and proof-of-concept. These trojans simulate outer misalignment (where the model’s behavior is misaligned with the specified reward function or objectives due to poorly defined or incorrect reward signals) rather than inner misalignment such as deceptive alignment (where the model appears aligned with the specified objectives but internally pursues different, misaligned goals). Moreover, activating a trojan typically results in an immediate change of behavior, while deception can be subtle, gradual, and, at first, entirely internal. Nevertheless, trojan detection can still provide a practical testbed for benchmarking interpretability methods .
Adversarial Robustness: There is a duality between interpretability and adversarial robustness . More interpretable models tend to be more robust against adversarial attacks , and vice versa, adversarially trained models are often more interpretable . For instance, techniques like input gradient regularization have been shown to simultaneously improve the interpretability of saliency maps and enhance adversarial robustness . Furthermore, interpretability tools can help create more sophisticated adversaries , improving our understanding of model internals. Viewing adversarial examples as inherent neural network features rather than bugs also hints at alien features beyond human perception. Connecting mechanistic interpretability to adversarial robustness thus promises ways to gain theoretical insight, measure progress , design inherently more robust architectures , and create interpretability-guided approaches for identifying (and mitigating) adversarial vulnerabilities .
More details on the interplay between interpretability, robustness, modularity, continual learning, network compression, and the human visual system can be found in the review by .
Corroborate or Refute Core Assumptions
Features are the fundamental units defining neural representations and enabling mechanistic interpretability’s bottom-up approach , but defining them involves assumptions requiring scrutiny, as they shape interpretations and research directions. Questioning hypotheses by seeking additional evidence or counter-examples is crucial.
The linear representation hypothesis treats activation directions as features , but the emergence and necessity of linearity is unclear – is it architectural bias or inherent? Stronger theory justifying linearity’s necessity or counter-examples like autoencoders on uncorrelated data without intermediate linear layers are needed. An alternative lens views features as polytopes from piecewise linear activations , questioning if direction simplification suffices or added polytope complexity aids interpretability.
The superposition hypothesis suggests that polysemantic neurons arise from the network compressing and representing many features within its limited set of neurons , but polysemanticity can also occur incidentally due to redundancy . Understanding superposition’s role could inform mitigating polysemanticity via regularization . Superposition also raises open questions like operationalizing computation in superposition, attention head superposition, representing feature clusters , connections to adversarial robustness , anti-correlated feature organization , and architectural effects .
Setting Standards
Prioritizing Robustness over Capability Advancement
As the mechanistic interpretability community expands, it is essential to maintain the norm of not advancing AI capabilities while simultaneously establishing metrics necessary for the field’s progress . Researchers should prioritize developing comprehensive tools for analyzing the worst-case performance of AI systems, ensuring robustness and reliability in critical applications. This includes focusing on adversarial tasks, such as backdoor detection and removal , and evaluating the accuracy of explanations in producing adversarial examples .
Establishing Metrics, Benchmarks, and Algorithmic Testbeds
A central challenge in mechanistic interpretability is the lack of rigorous evaluation methods. Relying solely on intuition can lead to conflating hypotheses with conclusions, resulting in cherry-picking and optimizing for best-case rather than average or worst-case performance . Current ad hoc practices and proxy measures risk over-optimization (Goodhart’s law – When a measure becomes a target, it ceases to be a good measure). Distinguishing correlation from causation is crucial, as interpretability illusions demonstrate that visualizations may be meaningless without causal linking .
To advance the field, rigorous evaluation methods are needed. These should include: (i) assessing out-of-distribution inputs, as most current methods are only valid for specific examples or datasets ; (ii) controlling systems through edits, such as implanting or removing trojans or targeted editing ; (iii) replacing components with simpler reverse-engineered alternatives ; and (iv) comprehensive evaluation through replacing components with hypothesized circuits .
Algorithmic testbeds are essential for evaluating faithfulness and falsifiability . Tools like Tracr can provide ground truth labels for benchmarking search methods , while toy models studying superposition in computation and transformers on algorithmic tasks can quantify sparsity and test intrinsic methods. Recently, introduced datasets of transformer weights with known circuits for evaluating mechanistic interpretability techniques.
Scaling Techniques
Broader and Deeper Coverage of Complex Models and Behaviors
A primary goal in scaling mechanistic interpretability is pushing the Pareto frontier between model and task complexity and the coverage of interpretability techniques . While efforts have focused on larger models, it is equally crucial to scale to more complex tasks and provide comprehensive explanations essential for provable safety and enumerative safety by ensuring models won’t engage in dangerous behaviors like deception. Future work should aim for thorough reverse engineering, integrating proven modules into larger networks , and capturing sequences encoded in hidden states beyond immediate predictions . Deepening analysis complexity is also key, validating the realism of toy models and extending techniques like path patching to larger language models. The field must move beyond small transformers on algorithmic tasks and limited scenarios to tackle more complex, realistic cases.
Towards Universality
As mechanistic interpretability matures, the field must transition from isolated empirical findings to developing overarching theories and universal reasoning primitives beyond specific circuits, aiming for a comprehensive understanding of AI capabilities. While collecting empirical data remains valuable , establishing motifs, empirical laws, and theories capturing universal model behavior aspects is crucial. This may involve finding more circuits/features , exploring circuits as a lens for memorization/generalization , identifying primitive general reasoning skills , generalizing specific findings to model-agnostic phenomena , and investigating emergent model generality across neural network classes . Identifying universal reasoning patterns and unifying theories is key to advancing interpretability.
Automation
Implementing automated methods is crucial for scaling interpretability of real-world state-of-the-art models across size, task complexity, behavior coverage, and analysis time . Manual circuit identification is labor-intensive , so automated techniques like circuit discovery and sparse autoencoders can enhance the process . Future work should automatically create varying datasets for understanding circuit functionality , develop automated hypothesis search , and investigate attention head/MLP interplay . Scaling sparse autoencoders to extract high-quality features automatically for frontier models is critical . Still, it requires caution regarding potential downsides like AI iteration outpacing training and loss of human interpretability from tool complexity .
Expanding Scope
Interpretability Across Training
While mechanistic interpretability of final trained models is a prerequisite, the field should also advance interpretability before and during training by studying learning dynamics . This includes tracking neuron development , analyzing neuron set changes with scale , and investigating emergent computations . Studying phase transitions could yield safety insights for reward hacking risks .
Multi-Level Analysis
Complementing the predominant bottom-up methods , mechanistic interpretability should explore top-down and hybrid approaches, a promising yet neglected avenue. The top-down analysis offers a tractable way to study large models and guide microscopic research with macroscopic observations . Its computational efficiency could enable extensive “comparative anatomy” of diverse models, revealing high-level motifs underlying abilities. These motifs could serve as analysis units for understanding internal modifications from techniques like instruction fine-tuning and reinforcement learning from human feedback .
New Frontiers: Vision, Multimodal, and Reinforcement Learning Models
While some mechanistic interpretability has explored convolutional neural networks for vision , vision-language models , and multimodal neurons , little work has focused on vision transformers . Future efforts could identify mechanisms within vision-language models, mirroring progress in unimodal language models .
Reinforcement learning (RL) is also a crucial frontier given its role in advanced AI training via techniques like reinforcement learning from human feedback (RLHF) , despite potentially posing significant safety risks . Interpretability of RL should investigate reward/goal representations , study circuitry changes from alignment algorithms , and explore emergent subgoals or proxies such as internal reward models . While current state-of-the-art AI systems as prediction-trained LLMs are considered relatively safe , progress on interpreting RL systems may prove critical for safeguarding the next paradigm .
Citation Information
Please cite as:
Bereska, L. & Gavves, E. Mechanistic Interpretability for AI Safety — A Review. TMLR (2024). https://openreview.net/forum?id=ePUVetPKu6.
BibTeX Citation:
@article{bereska_mechanistic_2024,title={Mechanistic Interpretability for AI Safety - A Review},author={Bereska, Leonard and Gavves, Efstratios},year={2024},month={Aug},journal={Transactions on Machine Learning Research},url={https://openreview.net/forum?id=ePUVetPKu6}}
Acknowledgements
I am grateful for the invaluable feedback and comments from Leon Lang, Tim Bakker, Jannik Brinkmann, Can Rager, Louis van Harten, Jacqueline Bereska, Benjamin Shaffrey, Thijmen Nijdam, Alice Rigg, Arthur Conmy, and Tom Lieberum. Their insights substantially improved this work.